Простым языком об HTTP / Habr
Вашему вниманию предлагается описание основных аспектов протокола HTTP — сетевого протокола, с начала 90-х и по сей день позволяющего вашему браузеру загружать веб-страницы. Данная статья написана для тех, кто только начинает работать с компьютерными сетями и заниматься разработкой сетевых приложений, и кому пока что сложно самостоятельно читать официальные спецификации.HTTP — широко распространённый протокол передачи данных, изначально предназначенный для передачи гипертекстовых документов (то есть документов, которые могут содержать ссылки, позволяющие организовать переход к другим документам).
Аббревиатура HTTP расшифровывается как HyperText Transfer Protocol, «протокол передачи гипертекста». В соответствии со спецификацией OSI, HTTP является протоколом прикладного (верхнего, 7-го) уровня. Актуальная на данный момент версия протокола, HTTP 1.1, описана в спецификации RFC 2616.
Протокол HTTP предполагает использование клиент-серверной структуры передачи данных. Клиентское приложение формирует запрос и отправляет его на сервер, после чего серверное программное обеспечение обрабатывает данный запрос, формирует ответ и передаёт его обратно клиенту. После этого клиентское приложение может продолжить отправлять другие запросы, которые будут обработаны аналогичным образом.
Задача, которая традиционно решается с помощью протокола HTTP — обмен данными между пользовательским приложением, осуществляющим доступ к веб-ресурсам (обычно это веб-браузер) и веб-сервером. На данный момент именно благодаря протоколу HTTP обеспечивается работа Всемирной паутины.
Также HTTP часто используется как протокол передачи информации для других протоколов прикладного уровня, таких как SOAP, XML-RPC и WebDAV. В таком случае говорят, что протокол HTTP используется как «транспорт».
API многих программных продуктов также подразумевает использование HTTP для передачи данных — сами данные при этом могут иметь любой формат, например, XML или JSON.
Как правило, передача данных по протоколу HTTP осуществляется через TCP/IP-соединения. Серверное программное обеспечение при этом обычно использует TCP-порт 80 (и, если порт не указан явно, то обычно клиентское программное обеспечение по умолчанию использует именно 80-й порт для открываемых HTTP-соединений), хотя может использовать и любой другой.
Как отправить HTTP-запрос?
Самый простой способ разобраться с протоколом HTTP — это попробовать обратиться к какому-нибудь веб-ресурсу вручную. Представьте, что вы браузер, и у вас есть пользователь, который очень хочет прочитать статьи Анатолия Ализара.
http://alizar.habrahabr.ru/
Соответственно вам, как веб-браузеру, теперь необходимо подключиться к веб-серверу по адресу alizar.habrahabr.ru.
Для этого вы можете воспользоваться любой подходящей утилитой командной строки. Например, telnet:
telnet alizar.habrahabr.ru 80
Сразу уточню, что если вы вдруг передумаете, то нажмите Ctrl + «]», и затем ввод — это позволит вам закрыть HTTP-соединение. Помимо telnet можете попробовать nc (или ncat) — по вкусу.
После того, как вы подключитесь к серверу, нужно отправить HTTP-запрос. Это, кстати, очень легко — HTTP-запросы могут состоять всего из двух строчек.
Для того, чтобы сформировать HTTP-запрос, необходимо составить стартовую строку, а также задать по крайней мере один заголовок — это заголовок Host, который является обязательным, и должен присутствовать в каждом запросе. Дело в том, что преобразование доменного имени в IP-адрес осуществляется на стороне клиента, и, соответственно, когда вы открываете TCP-соединение, то удалённый сервер не обладает никакой информацией о том, какой именно адрес использовался для соединения: это мог быть, например, адрес alizar.habrahabr.ru, habrahabr.ru или m.habrahabr.ru — и во всех этих случаях ответ может отличаться. Однако фактически сетевое соединение во всех случаях открывается с узлом 212.24.43.44, и даже если первоначально при открытии соединения был задан не этот IP-адрес, а какое-либо доменное имя, то сервер об этом никак не информируется — и именно поэтому этот адрес необходимо передать в заголовке Host.
Стартовая (начальная) строка запроса для HTTP 1.1 составляется по следующей схеме:
Метод URI HTTP/Версия
Например (такая стартовая строка может указывать на то, что запрашивается главная страница сайта):
GET / HTTP/1.1
Метод (в англоязычной тематической литературе используется слово method
URI (Uniform Resource Identifier, унифицированный идентификатор ресурса) — путь до конкретного ресурса (например, документа), над которым необходимо осуществить операцию (например, в случае использования метода GET подразумевается получение ресурса). Некоторые запросы могут не относиться к какому-либо ресурсу, в этом случае вместо URI в стартовую строку может быть добавлена звёздочка (астериск, символ «*»). Например, это может быть запрос, который относится к самому веб-серверу, а не какому-либо конкретному ресурсу. В этом случае стартовая строка может выглядеть так:
OPTIONS * HTTP/1.1
Версия определяет, в соответствии с какой версией стандарта HTTP составлен запрос. Указывается как два числа, разделённых точкой (например 1.1).
Для того, чтобы обратиться к веб-странице по определённому адресу (в данном случае путь к ресурсу — это «/»), нам следует отправить следующий запрос:
GET / HTTP/1.1Host: alizar.habrahabr.ru
При этом учитывайте, что для переноса строки следует использовать символ возврата каретки (Carriage Return), за которым следует символ перевода строки (Line Feed). После объявления последнего заголовка последовательность символов для переноса строки добавляется дважды.
Впрочем, в спецификации HTTP рекомендуется программировать HTTP-сервер таким образом, чтобы при обработке запросов в качестве межстрочного разделителя воспринимался символ LF, а предшествующий символ CR, при наличии такового, игнорировался. Соответственно, на практике бо́льшая часть серверов корректно обработает и такой запрос, где заголовки отделены символом LF, и он же дважды добавлен после объявления последнего заголовка.
Если вы хотите отправить запрос в точном соответствии со спецификацией, можете воспользоваться управляющими последовательностями \r и \n:
echo -en "GET / HTTP/1.1\r\nHost: alizar.habrahabr.ru\r\n\r\n" | ncat alizar.habrahabr.ru 80
Как прочитать ответ?
Стартовая строка ответа имеет следующую структуру:
HTTP/Версия Код состояния Пояснение
Версия протокола здесь задаётся так же, как в запросе.
Код состояния (Status Code) — три цифры (первая из которых указывает на класс состояния), которые определяют результат совершения запроса. Например, в случае, если был использован метод GET, и сервер предоставляет ресурс с указанным идентификатором, то такое состояние задаётся с помощью кода 200. Если сервер сообщает о том, что такого ресурса не существует — 404. Если сервер сообщает о том, что не может предоставить доступ к данному ресурсу по причине отсутствия необходимых привилегий у клиента, то используется код 403. Спецификация HTTP 1.1 определяет 40 различных кодов HTTP, а также допускается расширение протокола и использование дополнительных кодов состояний.
Пояснение к коду состояния (Reason Phrase) — текстовое (но не включающее символы CR и LF) пояснение к коду ответа, предназначено для упрощения чтения ответа человеком. Пояснение может не учитываться клиентским программным обеспечением, а также может отличаться от стандартного в некоторых реализациях серверного ПО.
После стартовой строки следуют заголовки, а также тело ответа. Например:
HTTP/1.1 200 OK
Server: nginx/1.2.1
Date: Sat, 08 Mar 2014 22:53:46 GMT
Content-Type: application/octet-stream
Content-Length: 7
Last-Modified: Sat, 08 Mar 2014 22:53:30 GMT
Connection: keep-alive
Accept-Ranges: bytes
Wisdom
Тело ответа следует через два переноса строки после последнего заголовка. Для определения окончания тела ответа используется значение заголовка Content-Length (в данном случае ответ содержит 7 восьмеричных байтов: слово «Wisdom» и символ переноса строки).
Смотрите сами:
HTTP/1.1 302 Moved Temporarily Server: nginx Date: Sat, 08 Mar 2014 22:29:53 GMT Content-Type: text/html Content-Length: 154 Connection: keep-alive Keep-Alive: timeout=25 Location: http://habrahabr.ru/users/alizar/ <html> <head><title>302 Found</title></head> <body bgcolor="white"> <center><h2>302 Found</h2></center> <hr><center>nginx</center> </body> </html>
В заголовке Location передан новый адрес. Теперь URI (идентификатор ресурса) изменился на /users/alizar/, а обращаться нужно на этот раз к серверу по адресу habrahabr.ru (впрочем, в данном случае это тот же самый сервер), и его же указывать в заголовке Host.
То есть:
GET /users/alizar/ HTTP/1.1Host: habrahabr.ru
В ответ на этот запрос веб-сервер Хабрахабра уже выдаст ответ с кодом 200 и достаточно большой документ в формате HTML.
Если вы уже успели вжиться в роль, то можете теперь прочитать полученный от сервера HTML-код, взять карандаш и блокнот, и нарисовать профайл Ализара — в принципе, именно этим бы на вашем месте браузер сейчас и занялся.
А что с безопасностью?
Сам по себе протокол HTTP не предполагает использование шифрования для передачи информации. Тем не менее, для HTTP есть распространённое расширение, которое реализует упаковку передаваемых данных в криптографический протокол SSL или TLS.
Название этого расширения — HTTPS (HyperText Transfer Protocol Secure). Для HTTPS-соединений обычно используется TCP-порт 443. HTTPS широко используется для защиты информации от перехвата, а также, как правило, обеспечивает защиту от атак вида man-in-the-middle — в том случае, если сертификат проверяется на клиенте, и при этом приватный ключ сертификата не был скомпрометирован, пользователь не подтверждал использование неподписанного сертификата, и на компьютере пользователя не были внедрены сертификаты центра сертификации злоумышленника.
На данный момент HTTPS поддерживается всеми популярными веб-браузерами.
А есть дополнительные возможности?
Протокол HTTP предполагает достаточно большое количество возможностей для расширения. В частности, спецификация HTTP 1.1 предполагает возможность использования заголовка Upgrade для переключения на обмен данными по другому протоколу. Запрос с таким заголовком отправляется клиентом. Если серверу требуется произвести переход на обмен данными по другому протоколу, то он может вернуть клиенту ответ со статусом «426 Upgrade Required», и в этом случае клиент может отправить новый запрос, уже с заголовком Upgrade.
Такая возможность используется, в частности, для организации обмена данными по протоколу WebSocket (протокол, описанный в спецификации RFC 6455, позволяющий обеим сторонам передавать данные в нужный момент, без отправки дополнительных HTTP-запросов): стандартное «рукопожатие» (handshake) сводится к отправке HTTP-запроса с заголовком Upgrade, имеющим значение «websocket», на который сервер возвращает ответ с состоянием «101 Switching Protocols», и далее любая сторона может начать передавать данные уже по протоколу WebSocket.
Что-то ещё, кстати, используют?
На данный момент существуют и другие протоколы, предназначенные для передачи веб-содержимого. В частности, протокол SPDY (произносится как английское слово speedy, не является аббревиатурой) является модификацией протокола HTTP, цель которой — уменьшить задержки при загрузке веб-страниц, а также обеспечить дополнительную безопасность.
Увеличение скорости обеспечивается посредством сжатия, приоритизации и мультиплексирования дополнительных ресурсов, необходимых для веб-страницы, чтобы все данные можно было передать в рамках одного соединения.
Опубликованный в ноябре 2012 года черновик спецификации протокола HTTP 2.0 (следующая версия протокола HTTP после версии 1.1, окончательная спецификация для которой была опубликована в 1999) базируется на спецификации протокола SPDY.
Многие архитектурные решения, используемые в протоколе SPDY, а также в других предложенных реализациях, которые рабочая группа httpbis рассматривала в ходе подготовки черновика спецификации HTTP 2.0, уже ранее были получены в ходе разработки протокола HTTP-NG, однако работы над протоколом HTTP-NG были прекращены в 1998.
На данный момент поддержка протокола SPDY есть в браузерах Firefox, Chromium/Chrome, Opera, Internet Exporer и Amazon Silk.
И что, всё?
В общем-то, да. Можно было бы описать конкретные методы и заголовки, но фактически эти знания нужны скорее в том случае, если вы пишете что-то конкретное (например, веб-сервер или какое-то клиентское программное обеспечение, которое связывается с серверами через HTTP), и для базового понимания принципа работы протокола не требуются. К тому же, всё это вы можете очень легко найти через Google — эта информация есть и в спецификациях, и в Википедии, и много где ещё.
Впрочем, если вы знаете английский и хотите углубиться в изучение не только самого HTTP, но и используемых для передачи пакетов TCP/IP, то рекомендую прочитать вот эту статью.
Ну и, конечно, не забывайте, что любая технология становится намного проще и понятнее тогда, когда вы фактически начинаете ей пользоваться.
Удачи и плодотворного обучения!
что должен знать каждый Web-разработчик / Habr
Как же все-таки работает HTTPS? Это вопрос, над которым я бился несколько дней в своем рабочем проекте.
Будучи Web-разработчиком, я понимал, что использование HTTPS для защиты пользовательских данных – это очень и очень хорошая идея, но у меня никогда не было кристального понимания, как HTTPS на самом деле устроен.
Как данные защищаются? Как клиент и сервер могут установить безопасное соединение, если кто-то уже прослушивает их канал? Что такое сертификат безопасности и почему я должен кому-то платить, чтобы получить его?
Трубопровод
Перед тем как мы погрузимся в то, как это работает, давайте коротко поговорим о том, почему так важно защищать Интернет-соединения и от чего защищает HTTPS.
Когда браузер делает запрос к Вашему любимому веб-сайту, этот запрос должен пройти через множество различных сетей, любая из которых может быть потенциально использована для прослушивания или для вмешательства в установленное соединение.
С вашего собственного компьютера на другие компьютеры вашей локальной сети, через роутеры и свитчи, через вашего провайдера и через множество других промежуточных провайдеров – огромное количество организаций ретранслирует ваши данные. Если злоумышленник окажется хотя бы в одной из них — у него есть возможность посмотреть, какие данные передаются.
Как правило, запросы передаются посредством обычного HTTP, в котором и запрос клиента, и ответ сервера передаются в открытом виде. И есть множество весомых аргументов, почему HTTP не использует шифрование по умолчанию:
• Для этого требуется больше вычислительных мощностей
• Передается больше данных
• Нельзя использовать кеширование
Но в некоторых случаях, когда по каналу связи передается исключительно важная информация (такая как, пароли или данные кредитных карт), необходимо обеспечить дополнительные меры, предотвращающие прослушивание таких соединений.
Transport Layer Security (TLS)
Сейчас мы собираемся погрузиться в мир криптографии, но нам не потребуется для этого какого-то особенного опыта — мы рассмотрим только самые общие вопросы. Итак, криптография позволяет защитить соединение от потенциальных злоумышленников, которые хотят воздействовать на соединение или просто прослушивать его.
TLS — наследник SSL — это такой протокол, наиболее часто применяемый для обеспечения безопасного HTTP соединения (так называемого HTTPS). TLS расположен на уровень ниже протокола HTTP в модели OSI. Объясняя на пальцах, это означает, что в процессе выполнения запроса сперва происходят все “вещи”, связанные с TLS-соединением и уже потом, все что связано с HTTP-соединением.
TLS – гибридная криптографическая система. Это означает, что она использует несколько криптографических подходов, которые мы и рассмотрим далее:
1) Асиметричное шифрование (криптосистема с открытым ключом) для генерации общего секретного ключа и аутентификации (то есть удостоверения в том, что вы – тот за кого себя выдаете).
2) Симметричное шифрование, использующее секретный ключ для дальнейшего шифрования запросов и ответов.
Криптосистема с открытым ключом
Криптосистема с открытым ключом – это разновидность криптографической системы, когда у каждой стороны есть и открытый, и закрытый ключ, математически связанные между собой. Открытый ключ используется для шифрования текста сообщения в “тарабарщину”, в то время как закрытый ключ используется для дешифрования и получения исходного текста.
С тех пор как сообщение было зашифровано с помощью открытого ключа, оно может быть расшифровано только соответствующим ему закрытым ключом. Ни один из ключей не может выполнять обе функции. Открытый ключ публикуется в открытом доступе без риска подвергнуть систему угрозам, но закрытый ключ не должен попасть к кому-либо, не имеющему прав на дешифровку данных. Итак, мы имеем ключи – открытый и закрытый. Одним из наиболее впечатляющих достоинств ассиметричного шифрования является то, что две стороны, ранее совершенно не знающие друг друга, могут установить защищенное соединение, изначально обмениваясь данными по открытому, незащищенному соединению.
Клиент и сервер используют свои собственные закрытые ключи (каждый – свой) и опубликованный открытый ключ для создания общего секретного ключа на сессию.
Это означает, что если кто-нибудь находится между клиентом и сервером и наблюдает за соединением – он все равно не сможет узнать ни закрытый ключ клиента, ни закрытый ключ сервера, ни секретный ключ сессии.
Как это возможно? Математика!
Алгоритм Ди́ффи — Хе́ллмана
Одним из наиболее распространенных подходов является алгоритм обмена ключами Ди́ффи — Хе́ллмана (DH). Этот алгоритм позволяет клиенту и серверу договориться по поводу общего секретного ключа, без необходимости передачи секретного ключа по соединению. Таким образом, злоумышленники, прослушивающие канал, не смогу определить секретный ключ, даже если они будут перехватывать все пакеты данных без исключения.
Как только произошел обмен ключами по DH-алгоритму, полученный секретный ключ может использоваться для шифрования дальнейшего соединения в рамках данной сессии, используя намного более простое симметричное шифрование.
Немного математики…
Математические функции, лежащие в основе этого алгоритма, имею важную отличительную особенность — они относительно просто вычисляются в прямом направлении, но практически не вычисляются в обратном. Это именно та область, где в игру вступают очень большие простые числа.
Пусть Алиса и Боб – две стороны, осуществляющие обмен ключами по DH-алгоритму. Сперва они договариваются о некотором основании root (обычно маленьком числе, таком как 2,3 или 5 ) и об очень большом простом числе prime (больше чем 300 цифр). Оба значения пересылаются в открытом виде по каналу связи, без угрозы компрометировать соединение.
Напомним, что и у Алисы, и у Боба есть собственные закрытые ключи (из более чем 100 цифр), которые никогда не передаются по каналам связи.
По каналу связи же передается смесь mixture, полученная из закрытых ключей, а также значений prime и root.
Таким образом:
Alice’s mixture = (root ^ Alice’s Secret) % prime
Bob’s mixture = (root ^ Bob’s Secret) % prime
где % — остаток от деления
Таким образом, Алиса создает свою смесь mixture на основе утвержденных значений констант (root и prime), Боб делает то же самое. Как только они получили значения mixture друг друга, они производят дополнительные математические операции для получения закрытого ключа сессии. А именно:
Вычисления Алисы
(Bob’s mixture ^ Alice’s Secret) % prime
Вычисления Боба
(Alice’s mixture ^ Bob’s Secret) % prime
Результатом этих операций является одно и то же число, как для Алисы, так и для Боба, и это число и становится закрытым ключом на данную сессию. Обратите внимание, что ни одна из сторон не должна была пересылать свой закрытый ключ по каналу связи, и полученный секретный ключ так же не передавался по открытому соединению. Великолепно!
Для тех, кто меньше подкован в математическом плане, Wikipedia дает прекрасную картинку, объясняющую данный процесс на примере смешивания цветов:
Обратите внимание как начальный цвет (желтый) в итоге превращается в один и тот же “смешанный” цвет и у Боба, и у Алисы. Единственное, что передается по открытому каналу связи так это наполовину смешанные цвета, на самом деле бессмысленные для любого прослушивающего канал связи.
Симметричное шифрование
Обмен ключами происходит всего один раз за сессию, во время установления соединения. Когда же стороны уже договорились о секретном ключе, клиент-серверное взаимодействие происходит с помощью симметричного шифрования, которое намного эффективнее для передачи информации, поскольку не требуется дополнительные издержки на подтверждения.
Используя секретный ключ, полученный ранее, а также договорившись по поводу режима шифрования, клиент и сервер могут безопасно обмениваться данными, шифруя и дешифруя сообщения, полученные друг от друга с использованием секретного ключа. Злоумышленник, подключившийся каналу, будет видеть лишь “мусор”, гуляющий по сети взад-вперед.
Аутентификация
Алгоритм Диффи-Хеллмана позволяет двум сторонам получить закрытый секретный ключ. Но откуда обе стороны могут уверены, что разговаривают действительно друг с другом? Мы еще не говорили об аутентификации.
Что если я позвоню своему приятелю, мы осуществим DH-обмен ключами, но вдруг окажется, что мой звонок был перехвачен и на самом деле я общался с кем-то другим?! Я по прежнему смогу безопасно общаться с этим человеком – никто больше не сможет нас прослушать – но это будет совсем не тот, с кем я думаю, что общаюсь. Это не слишком безопасно!
Для решения проблемы аутентификации, нам нужна Инфраструктура открытых ключей, позволяющая быть уверенным, что субъекты являются теми за кого себя выдают. Эта инфраструктура создана для создания, управления, распространения и отзыва цифровых сертификатов. Сертификаты – это те раздражающие штуки, за которые нужно платить, чтобы сайт работал по HTTPS.
Но, на самом деле, что это за сертификат, и как он предоставляет нам безопасность?
Сертификаты
В самом грубом приближении, цифровой сертификат – это файл, использующий электронной-цифровую подпись (подробнее об этом через минуту) и связывающий открытый (публичный) ключ компьютера с его принадлежностью. Цифровая подпись на сертификате означает, что некто удостоверяет тот факт, что данный открытый ключ принадлежит определенному лицу или организации.
По сути, сертификаты связывают доменные имена с определенным публичным ключом. Это предотвращает возможность того, что злоумышленник предоставит свой публичный ключ, выдавая себя за сервер, к которому обращается клиент.
В примере с телефоном, приведенном выше, хакер может попытаться предъявить мне свой публичный ключ, выдавая себя за моего друга – но подпись на его сертификате не будет принадлежать тому, кому я доверяю.
Чтобы сертификату доверял любой веб-браузер, он должен быть подписан аккредитованным удостоверяющим центром (центром сертификации, Certificate Authority, CA). CA – это компании, выполняющие ручную проверку, того что лицо, пытающееся получить сертификат, удовлетворяет следующим двум условиям:
1. является реально существующим;
2. имеет доступ к домену, сертификат для которого оно пытается получить.
Как только CA удостоверяется в том, что заявитель – реальный и он реально контролирует домен, CA подписывает сертификат для этого сайта, по сути, устанавливая штамп подтверждения на том факте, что публичный ключ сайта действительно принадлежит ему и ему можно доверять.
В ваш браузер уже изначально предзагружен список аккредитованных CA. Если сервер возвращает сертификат, не подписанный аккредитованным CA, то появится большое красное предупреждение. В противном случае, каждый мог бы подписывать фиктивные сертификаты.
Так что даже если хакер взял открытый ключ своего сервера и сгенерировал цифровой сертификат, подтверждающий что этот публичный ключ, ассоциирован с сайтом facebook.com, браузер не поверит в это, поскольку сертификат не подписан аккредитованным CA.
Прочие вещи которые нужно знать о сертификатах
Расширенная валидация
В дополнение к обычным X.509 сертификатам, существуют Extended validation сертификаты, обеспечивающие более высокий уровень доверия. Выдавая такой сертификат, CA совершает еще больше проверок в отношении лица, получающего сертификат (обычно используя паспортные данные или счета).
При получение такого сертификата, браузер отображает в адресной строке зеленую плашку, в дополнение к обычной иконке с замочком.
Обслуживание множества веб-сайтов на одном сервере
Поскольку обмен данными по протоколу TLS происходит еще до начала HTTP соединения, могут возникать проблемы в случае, если несколько веб-сайтов расположены на одном и том же веб-сервере, по тому же IP-адресу. Роутинг виртуальных хостов осуществляется веб-сервером, но TLS-соединение возникает еще раньше. Единый сертификат на весь сервер будет использоваться при запросе к любому сайту, расположенному на сервере, что может вызвать проблемы на серверах с множеством хостов.
Если вы пользуетесь услугами веб-хостинга, то скорее всего вам потребуется приобрести выделенный IP-адрес, для того чтобы вы могли использовать у себя HTTPS. В противном случае вам придется постоянно получать новые сертификаты (и верифицировать их) при каждом обновлении сайта.
По этой теме много данных есть в википедии, есть курс на Coursera. Отдельное спасибо ребятам из чата на security.stackexchange.com, которые отвечали на мои вопросы сегодня утром.
Примечания переводчика:
1)Спасибо хабраюзеру wowkin за отличную ссылку по теме (видео переведено и озвученно хабраюзером freetonik):
2) По результатам развернувшейся в коменатариях дискуссии (спасибо за участие хабраюзерам a5b, Foggy4 и Allen) дополняю основную статью следующей информацией:
По данным netcraft на базе свежего SSL survey (2.4 млн SSL сайтов, июнь 2013), большинство SSL соединений не используют Perfect forward secrecy алгоритмы: news.netcraft.com/archives/2013/06/25/ssl-intercepted-today-decrypted-tomorrow.html
Особенно ситуация плоха в случае с IE (даже 10 версии), который поддерживает Диффи-Хеллмана только на эллиптических кривых (RSA и ECDSA сертификаты), либо классический Диффи-Хеллман с более редкими сертификатами DSS (DSA).
По подсчетам netcraft 99,7 % соединений с IE и по 66% — с Chrome, Opera и Firefox не будут использовать Диффи-Хеллмана.
На Hacker News в обсуждении это тоже заметили.
Also (and I made the same mistake in my talk…), yes, explaining DH is important, but now it kind of sounds like in TLS both sides figure out the master secret using DH (and, in your talk, specifically, regular DH, not EC-based DH), when in reality that depends on the ciphersuite, and the vast majority of TLS connections don’t work that way. From what I understand to be most TLS configurations in the wild, the pre-master secret is encrypted using the server’s public key. (RFC 5246: 7.4.7.1, 8.1.1)это важно и интересно, но не все понимают что он в реальности применяется не так часто. В большинстве сеансов SSL и TLS действительно обмен ключей происходит путем их шифрования с помощью RSA.
Что такое протокол HTTP и как он работает

Более чем за три десятка лет Интернет проник во все области деятельности человечества: его используют для того, чтобы читать книги, смотреть видео, любоваться картинками с котиками, узнавать погоду, слушать музыку и признаваться в любви. Почти весь бизнес так или иначе использует Сеть для передачи информации о сотрудниках, поступлениях товаров на склады и перевода денежных средств. Большая часть данных, которая передаётся через Сеть, использует протокол HTTP в качестве контейнера. Каждый раз, когда вы заходите на сайт, ваш браузер посылает до нескольких десятков HTTP запросов. HTTP используется для загрузки файлов из сети, программы скачивают обновления, используя этот протокол, даже интернет радио не обходится без него.
Что же привело к столь широкому распространению этого формата передачи данных?
История HTTP
HyperText Transfer Protocol был создан в CERN в 1991 году Тимом Бернерсоном-Ли, во времена, когда призрак Интернета бродил по земному шарику. Как и многие великие изобретения, он создавался не ради каких-то абстрактных целей, а ради удобства автора и решал конкретную проблему: давал доступ к гигантскому количеству информационных ресурсов лаборатории. Документацию и экспериментальные данные необходимо было не только хранить, но обеспечивать к ним доступ для сотен специалистов и институтов по всему миру. HTTP был придуман с целью упростить доступ к информации и оказался настолько удобен, что в 1993 году была опубликована спецификация HTTP/0.9, доступная каждому. В ней описывался базовый синтаксис протокола, давались определения базовым понятиям и подготавливалась почва для дальнейшего расширения протокола. Также были опубликованы исходные коды браузера (программы для просмотра гипертекста, передаваемого через HTTP) под названием, вы не поверите, WorldWideWeb:

Так мировая сеть сделала свой первый шаг.
Первоначально HTTP использовался исключительно для передачи гипертекста (текста с перекрёстными ссылками) между компьютерами, но позже оказалось, что он прекрасно подходит и для того, чтобы посылать на ПК пользователя бинарные данные — например, изображения или музыку.
В мае 1996 года, всего через три года после первого релиза, была выпущена спецификация HTTP/1.0 (RFC1945), которая расширяла исходную версию протокола, закрепляла коды ответа и вводила новый тип данных для передачи — application/octet-stream, что фактически «легализовало» передачу нетекстовых данных.
В июне 1999 года была опубликована версия протокола 1.1, которая фактически оставалась неизменной на протяжении 16 лет! Более того, она послужила основой для многих других протоколов, в частности WebSocket и WebDav.
И, наконец, 11 февраля 2015 года вышла черновая версия протокола HTTP/2. В отличие от предыдущих двух релизов, он не является переработанным HTTP/0.9, имеет не текстовый, а бинарный формат представления данных, требует обязательного шифрования и имеет множество более мелких отличий от своих предков: сжатие заголовков, использование одного TCP соединения для серии запросов, а также даёт возможность послать серверу дополнительные данные в теле ответа, превентивно отдавая ресурсы в браузер. Более подробно эта версия протокола будет рассмотрена в одной из следующих статей.
Как работает HTTP/1.1

В основе протокола HTTP лежит концепция клиент-серверной архитектуры: клиент, чаще всего браузер, делает запрос на сервер. Существует множество видов запросов, самые распространённые — это GET и POST: первый означает, что клиент хочет получить данные, а второй — что клиент хочет послать данные на сервер. Таким образом, общение между клиентом и сервером сводится к обмену сообщениями, причём всегда по принципу «клиент послал запрос — сервер прислал ответ».
Разберём модельную ситуацию: Петя зовет Колю погулять. Он открывает страничку ВК (или другой социальной сети) и пишет приглашение, после чего нажимает кнопку «Отправить». Что же происходит при этом? Браузер берёт текст приглашения Пети, упаковывает его какой-нибудь промежуточный формат (например, json) и посылает на сервер в виде POST сообщения. Если всё прошло удачно, то сервер ВК в ответ присылает сообщение с кодом 201 («CREATED» — «создано»).
Теперь мысленно обратимся к Коле, который открыл страничку своей любимой социальной сети. При этом браузер послал на сервер GET запрос. Сервер, на который Петя уже послал своё приглашение, видит, что Коля проверяет свои входящие, и отвечает на запрос сообщением, содержащим код 200 (буквально означает «OK»).

Таким образом, любое взаимодействие между сервером и клиентом можно разбить на пары «вопрос-ответ», что очень упрощает взаимодействие с веб-сервисами.
Внутреннее устройство протокола
Чем же на самом деле обмениваются клиент и сервер между собой?
Как было замечено выше, протокол HTTP до версии 2.0 (и мы будем рассматривать версию 1.1 как самую распространенную до сих пор) имеет текстовую природу. Фактически клиент посылает на сервер специальным образом составленное «письмо»:
——————————————————
GET /im HTTP/1.1
Host: vk.com
User-Agent: Mozilla/5.0 (X11; U; Linux i686; ru; rv:1.9b5) Gecko/2008050509 Firefox/3.0b5
Accept: text/html
Connection: close
——————————————————
Давайте разберём его построчно.
Первая строка содержит в себе название метода (GET), URI — универсальный идентификатор ресурса (/im в данном случае), и версию используемого протокола — HTTP/1.1.
После этой обязательной строки, с которой начинается любое HTTP-сообщение, идут несколько пар значений, разделённых двоеточиями. Они называются заголовками (HTTP-headers). Эти значения могут быть самыми разными, но наиболее распространенными являются Host (содержит имя сайта, наличие такого заголовка позволяет хостить несколько сайтов на одном IP адресе) и User-Agent, который по задумке должен обозначать вид используемого браузера, а на практике сложным образом описывает список поддерживаемых браузером технологий. Поле Accept определяет формат данных в ответе, который нужен клиенту, а «Connection: close» означает, что клиент хочет закрыть TCP соединение сразу после получения ответа от сервера.
Если запрос сформирован правильно, и сервер функционирует нормально, и сеть в порядке (как много этих «если»…), то в ответ на HTTP пакет от клиента придёт ответ, который выглядит примерно вот так:
——————————————————
HTTP/1.1 200 OK
Date: Wed, 27 Aug 2017 09:50:20 GMT
Server: Apache
X-Powered-By: PHP/5.2.4-2ubuntu5wm1
Content-Language: ru
Content-Type: text/html; charset=utf-8
Content-Length: 18
Connection: close
Го гулять
——————————————————
Здесь мы наблюдаем отсутствие названия метода в первой строке, и ряд новых заголовков, из которых я рекомендую обратить внимание на поле «Content-Length: 18». Это число обозначает длину данных в байтах, которые передаются после пустой строки в конце пакета (так как в заголовке Content-Type указана кодировка utf-8, то каждая буква кириллицы в сообщении занимает два байта). Таким образом мы рассмотрели простой пример работы протокола HTTP.
HTTP позволяет миллиардам людей получать доступ новостям, письмам друзей, спорам о самолёте на конвейерной ленте, смешным фотографиям котиков и данным о недавно открытом в БАКе гамма-резонансе (есть что-то трогательное в том, что HTTP по-прежнему приносит пользу на своей малой родине, ЦЕРНе). Мало какие изобретения обладают столь мощным влиянием на человечество в том объёме, как этот простенький протокол передачи структурированного текста. И, разумеется, такой протокол не мог остаться без расширений, и самым популярным из них стал HTTPS — о нем и поговорим в следующей статье.
HTTPS — Википедия
HTTPS (аббр. от англ. HyperText Transfer Protocol Secure) — расширение протокола HTTP для поддержки шифрования в целях повышения безопасности. Данные в протоколе HTTPS передаются поверх криптографических протоколов TLS или устаревшего в 2015 году — SSL . В отличие от HTTP с TCP-портом 80, для HTTPS по умолчанию используется TCP-порт 443.[1]
Протокол был разработан компанией Netscape Communications для браузера Netscape Navigator в 1994 году[2].
HTTPS не является отдельным протоколом. Это обычный HTTP, работающий через шифрованные транспортные механизмы SSL и TLS.[3] Он обеспечивает защиту от атак, основанных на прослушивании сетевого соединения — от снифферских атак и атак типа man-in-the-middle, при условии, что будут использоваться шифрующие средства и сертификат сервера проверен и ему доверяют.[4]
По умолчанию HTTPS URL использует 443 TCP-порт (для незащищённого HTTP — 80).[1] Чтобы подготовить веб-сервер для обработки https-соединений, администратор должен получить и установить в систему сертификат открытого и закрытого ключа для этого веб-сервера. В TLS используется как асимметричная схема шифрования (для выработки общего секретного ключа), так и симметричная (для обмена данными, зашифрованными общим ключом). Сертификат открытого ключа подтверждает принадлежность данного открытого ключа владельцу сайта. Сертификат открытого ключа и сам открытый ключ посылаются клиенту при установлении соединения; закрытый ключ используется для расшифровки сообщений от клиента.[5]
Существует возможность создать такой сертификат, не обращаясь в ЦС. Подписываются такие сертификаты этим же сертификатом и называются самоподписанными (self-signed). Без проверки сертификата каким-то другим способом (например, звонок владельцу и проверка контрольной суммы сертификата) такое использование HTTPS подвержено атаке man-in-the-middle.[6]
Эта система также может использоваться для аутентификации клиента, чтобы обеспечить доступ к серверу только авторизованным пользователям. Для этого администратор обычно создаёт сертификаты для каждого пользователя и загружает их в браузер каждого пользователя. Также будут приниматься все сертификаты, подписанные организациями, которым доверяет сервер. Такой сертификат обычно содержит имя и адрес электронной почты авторизованного пользователя, которые проверяются при каждом соединении, чтобы проверить личность пользователя без ввода пароля.[7]
В HTTPS для шифрования используется длина ключа 40, 56, 128 или 256 бит. Некоторые старые версии браузеров используют длину ключа 40 бит (пример тому — IE версий до 4.0), что связано с экспортными ограничениями в США. Длина ключа 40 бит не является сколько-нибудь надёжной. Многие современные сайты требуют использования новых версий браузеров, поддерживающих шифрование с длиной ключа 128 бит, с целью обеспечить достаточный уровень безопасности. Такое шифрование значительно затрудняет злоумышленнику поиск паролей и другой личной информации.[5]
Традиционно на одном IP-адресе может работать только один HTTPS-сайт. Для работы нескольких HTTPS-сайтов с различными сертификатами применяется расширение TLS под названием Server Name Indication (SNI)[8].
На 17 июля 2017 года, 22,67 % сайтов из списка «Alexa top 1,000,000» используют протокол HTTPS по умолчанию[9]. HTTPS используется на 4,04 % от общего числа зарегистрированных российских доменов[10].
Идентификация сервера[править | править код]
HTTP/TLS запросы генерируются путём разыменования URI, вследствие чего имя хоста становится известно клиенту. В начале общения, сервер посылает клиенту свой сертификат, чтобы клиент идентифицировал его. Это позволяет предотвратить атаку человек посередине. В сертификате указывается URI сервера. Согласование имени хоста и данных, указанных в сертификате, происходит в соответствии с протоколом RFC2459[11].
Если имя сервера не совпадает с указанным в сертификате, то пользовательские программы, например браузеры, сообщают об этом пользователю. В основном, браузеры предоставляют пользователю выбор: продолжить незащищённое соединение или прервать его.[12]
Идентификация клиента[править | править код]
Обычно, сервер не располагает достаточной информацией о клиенте, для его идентификации. Однако, для обеспечения повышенной защищённости соединения используется так называемая two-way authentication. При этом сервер, после подтверждения его сертификата клиентом, также запрашивает сертификат. Таким образом, схема подтверждения клиента аналогична идентификации сервера.[13]
Совместное использование HTTP и HTTPS[править | править код]
Когда сайты используют смешанную функциональность HTTP и HTTPS, это потенциально приводит к информационной угрозе для пользователя. Например, если основные страницы некоторого сайта загружаются, используя HTTPS, а CSS и JavaScript загружаются по HTTP, то злоумышленник в момент загрузки последних может подгрузить свой код и получить данные HTML-страницы. Многие сайты, несмотря на такие уязвимости, загружают контент через сторонние сервисы, которые не поддерживают HTTPS. Механизм HSTS позволяет предотвратить подобные уязвимости, заставляя принудительно использовать HTTPS соединение даже там, где по умолчанию используется HTTP.[14]
Атаки с использованием анализа трафика[править | править код]
В HTTPS были обнаружены уязвимости, связанные с анализом трафика. Атака с анализом трафика — это тип атаки, при которой выводятся свойства защищённых данных канала путём измерения размера трафика и времени передачи сообщений в нём. Анализ трафика возможен, поскольку шифрование SSL/TLS изменяет содержимое трафика, но оказывает минимальное влияние на размер и время прохождения трафика. В мае 2010 года исследователи из Microsoft Research и Университета Индианы обнаружили, что подробные конфиденциальные пользовательские данные могут быть получены из второстепенных данных, таких например, как размеры пакетов. Анализатор трафика смог заполучить историю болезней, данные об использовавшихся медикаментах и проведённых операциях пользователя, данные о семейном доходе и пр. Всё это было произведено несмотря на использование HTTPS в нескольких современных веб-приложениях в сфере здравоохранения, налогообложения и других.[15]
Человек посередине. HTTPS[править | править код]
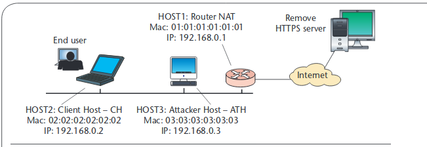 Рис.1 Стандартная конфигурация сети. Пользователь на хосте клиента (CH) хочет осуществить безопасную транзакцию, но уязвим для атаки «человек в середине».
Рис.1 Стандартная конфигурация сети. Пользователь на хосте клиента (CH) хочет осуществить безопасную транзакцию, но уязвим для атаки «человек в середине».При атаке «человек посередине» используется то, что сервер HTTPS отправляет сертификат с открытым ключом в браузер. Если этот сертификат не заслуживает доверия, то канал передачи будет уязвимым для атаки злоумышленника. Такая атака заменяет оригинальный сертификат, удостоверяющий HTTPS-сервер, модифицированным сертификатом. Атака проходит успешно, если пользователь пренебрегает двойной проверкой сертификата, когда браузер отправляет предупреждение. Это особенно распространено среди пользователей, которые часто сталкиваются с самозаверенными сертификатами при доступе к сайтам внутри сети частных организаций. [16]
На рис. 1 представлена ситуация, когда злоумышленник является шлюзом между клиентом, осуществляющим безопасную транзакцию, и сервером. Таким образом через злоумышленника проходит весь трафик клиента и он может перенаправить его по своему усмотрению. Здесь делаются следующие шаги:
- Злоумышленник встраивается между клиентом и сервером
- Пересылает все сообщения от клиента серверу без изменений
- Перехват сообщений от сервера, посланных по шлюзу по умолчанию
- Создание самозаверенного сертификата и подмена им сертификата сервера
- Отправление ложного сертификата клиенту
- Когда клиент подтвердит сертификат, будут установлены защищённые соединения: между злоумышленником и сервером и другое — между злоумышленником и клиентом.
В итоге такой атаки клиент и сервер думают, что осуществляют безопасное соединение, однако злоумышленник теперь также имеет закрытый ключ и может расшифровать любое сообщение в канале.[16]
- ↑ 1 2 E. Rescorla. HTTP Over TLS (англ.). tools.ietf.org. Дата обращения 25 декабря 2017.
- ↑ Walls, Colin. Embedded software (неопр.). — Newnes, 2005. — С. 344. — ISBN 0-7506-7954-9.
- ↑ E. Rescorla. HTTP Over TLS (англ.). tools.ietf.org. Дата обращения 25 декабря 2017.
- ↑ E. Rescorla. HTTP Over TLS (англ.). tools.ietf.org. Дата обращения 25 декабря 2017.
- ↑ 1 2 Tim Dierks <[email protected]>. The Transport Layer Security (TLS) Protocol Version 1.2 (англ.). tools.ietf.org. Дата обращения 25 декабря 2017.
- ↑ E. Rescorla. HTTP Over TLS (англ.). tools.ietf.org. Дата обращения 25 декабря 2017.
- ↑ Aboba, Bernard, Simon, Dan. PPP EAP TLS Authentication Protocol (англ.). buildbot.tools.ietf.org. Дата обращения 25 декабря 2017.
- ↑ Shbair et al, 2015, pp. 990–995.
- ↑ HTTPS usage statistics on top websites (неопр.). statoperator.com. Дата обращения 28 июня 2016.
- ↑ Статистика российского интернета runfo.ru (рус.). www.runfo.ru. Дата обращения 16 февраля 2017.
- ↑ Solo, David, Housley, Russell, Ford, Warwick. Certificate and CRL Profile (англ.). tools.ietf.org. Дата обращения 22 декабря 2017.
- ↑ E. Rescorla. HTTP Over TLS (англ.). tools.ietf.org. Дата обращения 22 декабря 2017.
- ↑ Tim Dierks <[email protected]>. The Transport Layer Security (TLS) Protocol Version 1.2 (англ.). tools.ietf.org. Дата обращения 22 декабря 2017.
- ↑ How to Deploy HTTPS Correctly (англ.), Electronic Frontier Foundation (15 November 2010). Дата обращения 23 декабря 2017.
- ↑ Shuo Chen, Rui Wang, XiaoFeng Wang, Kehuan Zhang. Side-Channel Leaks in Web Applications: a Reality Today, a Challenge Tomorrow (en-us) // Microsoft Research. — 2010-05-01.
- ↑ 1 2 Callegati et al, 2009, с. 78.
- Shuo Chen, Rui Wang, XiaoFeng Wang, Kehuan Zhang. Side-Channel Leaks in Web Applications: a Reality Today, a Challenge Tomorrow (en-us) // Microsoft Research. — 2010-05-01.
- F. Callegati, W. Cerroni, M. Ramilli. Man-in-the-Middle Attack to the HTTPS Protocol // IEEE Security Privacy. — 2009. — Январь (т. 7, вып. 1). — С. 78—81. — ISSN 1540-7993. — DOI:10.1109/MSP.2009.12.
- W. M. Shbair, T. Cholez, A. Goichot, I. Chrisment. Efficiently bypassing SNI-based HTTPS filtering // 2015 IFIP/IEEE International Symposium on Integrated Network Management (IM). — 2015. — Май. — DOI:10.1109/INM.2015.7140423.
Обзор протокола HTTP — Веб-технологии для разработчиков
HTTP — это протокол, позволяющий получать различные ресурсы, например HTML-документы. Протокол HTTP лежит в основе обмена данными в Интернете. HTTP является протоколом клиент-серверного взаимодействия, что означает инициирование запросов к серверу самим получателем, обычно веб-браузером (web-browser). Полученный итоговый документ будет (может) состоять из различных поддокументов являющихся частью итогового документа: например, из отдельно полученного текста, описания структуры документа, изображений, видео-файлов, скриптов и многого другого.
Клиенты и серверы взаимодействуют, обмениваясь одиночными сообщениями (а не потоком данных). Сообщения, отправленные клиентом, обычно веб-бруезером, называются запросами, а сообщения, отправленные сервером, называются ответами.
Хотя HTTP был разработан еще в начале 1990-х годов, за счет своей расширяемости в дальнейшем он все время совершенствовался. HTTP является протоколом прикладного уровня, который чаще всего использует возможности другого протокола — TCP (или TLS — защищённый TCP) — для пересылки своих сообщений, однако любой другой надежный транспортный протокол теоретически может быть использован для доставки таких сообщений. Благодаря своей расширяемости, он используется не только для получения клиентом гипертекстовых документов, изображений и видео, но и для передачи содержимого серверам, например, с помощью HTML-форм. HTTP также может быть использован для получения только частей документа с целью обновления веб-страницы по запросу (например посредством AJAX запроса).
Составляющие систем, основанных на HTTP
HTTP — это клиент-серверный протокол, то есть запросы отправляются какой-то одной стороной — участником обмена (user-agent) (либо прокси вместо него). Чаще всего в качестве участника выступает веб-браузер, но им может быть кто угодно, например, робот, путешествующий по Сети для пополнения и обновления данных индексации веб-страниц для поисковых систем.
Каждый запрос (англ. request) отправляется серверу, который обрабатывает его и возвращает ответ (англ. response). Между этими запросами и ответами как правило существуют многочисленные посредники, называемые прокси, которые выполняют различные операции и работают как шлюзы или кэш, например.
Обычно между браузером и сервером гораздо больше различных устройств-посредников, которые играют какую-либо роль в обработке запроса: маршрутизаторы, модемы и так далее. Благодаря тому, что Сеть построена на основе системы уровней (слоёв) взаимодействия, эти посредники «спрятаны» на сетевом и транспортном уровнях. В этой системе уровней HTTP занимает самый верхний уровень, который называется «прикладным» (или «уровнем приложений»). Знания об уровнях сети, таких как представительский, сеансовый, транспортный, сетевой, канальный и физический, имеют важное значение для понимания работы сети и диагностики возможных проблем, но не требуются для описания и понимания HTTP.
Клиент: участник обмена
Участник обмена (user agent) — это любой инструмент или устройство, действующие от лица пользователя. Эту задачу преимущественно выполняет веб-браузер; в некоторых случаях участниками выступают программы, которые используются инженерами и веб-разработчиками для отладки своих приложений.
Браузер всегда является той сущностью, которая создаёт запрос. Сервер обычно этого не делает, хотя за многие годы существования сети были придуманы способы, которые могут позволить выполнить запросы со стороны сервера.
Чтобы отобразить веб страницу, браузер отправляет начальный запрос для получения HTML-документа этой страницы. После этого браузер изучает этот документ, и запрашивает дополнительные файлы, необходимые для отбражения содержания веб-страницы (исполняемые скрипты, информацию о макете страницы — CSS таблицы стилей, дополнительные ресурсы в виде изображений и видео-файлов), которые непосредственно являются частью исходного документа, но расположены в других местах сети. Далее браузер соединяет все эти ресурсы для отображения их пользователю в виде единого документа — веб-страницы. Скрипты, выполняемые самим браузером, могут получать по сети дополнительные ресурсы на последующих этапах обработки веб-страницы, и браузер соответствующим образом обновляет отображение этой страницы для пользователя.
Веб-страница является гипертекстовый документом. Это означает, что некоторые части отображаемого текста являются ссылками, которые могут быть активированы (обычно нажатием кнопки мыши) с целью получения и соответственно отображения новой веб-страницы (переход по ссылке). Это позволяет пользователю «перемещаться» по страницам сети (Internet). Браузер преобразует эти гиперссылки в HTTP-запросы и в дальнейшем полученные HTTP-ответы отображает в понятном для пользователя виде.
Веб-сервер
На другой стороне коммуникационного канала расположен сервер, который обслуживает (англ. serve) пользователя, предоставляя ему документы по запросу. С точки зрения конечного пользователя, сервер всегда является некой одной виртуальной машиной, полностью или частично генерирующей документ, хотя фактически он может быть группой серверов, между которыми балансируется нагрузка, то есть перераспределяются запросы различных пользователей, либо сложным программным обеспечением, опрашивающим другие компьютеры (такие как кэширующие серверы, серверы баз данных, серверы приложений электронной коммерции и другие).
Сервер не обязательно расположен на одной машине, и наоборот — несколько серверов могут быть расположены (хоститься) на одной и той же машине. В соответствии с версией HTTP/1.1 и имея Host заголовок, они даже могут делить тот же самый IP-адрес.
Прокси
Между веб-браузером и сервером находятся большое количество сетевых узлов передающих HTTP сообщения. Из за слоистой структуры, большинство из них оперируют также на транспортном сетевом или физическом уровнях, становясь прозрачным на HTTP слое и потенциально снижая производительность. Эти операции на уровне приложений называются прокси. Они могут быть прозрачными, или нет, (изменяющие запросы не пройдут через них), и способны исполнять множество функций:
- caching (кеш может быть публичным или приватными, как кеш браузера)
- фильтрация (как сканирование антивируса, родительский контроль, …)
- выравнивание нагрузки (позволить нескольким серверам обслуживать разные запросы)
- аутентификация (контролировать доступом к разным ресурсам)
- протоколирование (разрешение на хранение истории операций)
Основные аспекты HTTP
HTTP — прост
Даже с большей сложностью, введенной в HTTP/2 путем инкапсуляции HTTP-сообщений в фреймы, HTTP, как правило, прост и удобен для восприятия человеком. HTTP-сообщения могут читаться и пониматься людьми, обеспечивая более легкое тестирование разработчиков и уменьшенную сложность для новых пользователей.
HTTP — расширяемый
Введенные в HTTP/1.0 HTTP-заголовки сделали этот протокол легким для расширения и экспериментирования. Новая функциональность может быть даже введена простым соглашением между клиентом и сервером о семантике нового заголовка.
HTTP не имеет состояния, но имеет сессию
HTTP не имеет состояния: не существует связи между двумя запросами, которые последовательно выполняются по одному соединению. Из этого немедленно следует возможность проблем для пользователя, пытающегося взаимодействовать с определенной страницей последовательно, например, при использовании корзины в электронном магазине. Но хотя ядро HTTP не имеет состояния, куки позволяют использовать сессии с сохранением состояния. Используя расширяемость заголовков, куки добавляются к рабочему потоку, позволяя сессии на каждом HTTP-запросе делиться некоторым контекстом, или состоянием.
HTTP и соединения
Содинение управляется на транспортном уровне, и потому принципиально выходит за границы HTTP. Хотя HTTP не требует, чтобы базовый транспортного протокол был основан на соединениях, требуя только надёжность, или отсутствие потерянных сообщений (т.е. как минимум представление ошибки). Среди двух наиболее распространенных транспортных протоколов Интернета, TCP надёжен, а UDP — нет. HTTP впоследствии полагается на стандарт TCP, являющийся основанным на соединениях, несмотря на то, что соединение не всегда требуется.
HTTP/1.0 открывал TCP-соединение для каждого обмена запросом/ответом, имея два важных недостатка: открытие соединения требует нескольких обменов сообщениями, и потому медленно, хотя становится более эффективным при отправке нескольких сообщений, или при регулярной отправке сообщений: теплые соединения более эффективны, чем холодные.
Для смягчения этих недостатков, HTTP/1.1 предоставил конвеерную обработку (которую оказалось трудно реализовать) и устойчивые соединения: лежащее в основе TCP соединение можно частично контролировать через заголовок Connection. HTTP/2 сделал следующий шаг, добавив мультиплексирование сообщений через простое соединение, помогающее держать соединение теплым и более эффективным.
Проводятся эксперименты по разработке лучшего транспортного протокола, более подходящего для HTTP. Например, Google эксперементирует с QUIC, которая основана на UDP, для предоставления более надёжного и эффективного транспортного протокола.
Чем можно управлять через HTTP
Естественная расширяемость HTTP со временем позволила большее управление и функциональность Сети. Кэш и методы аутентификации были ранними функциями в истории HTTP. Способность ослабить первоначальные ограничения, напротив, была добавлена в 2010-е.
Ниже перечислены общие функции, управляемые с HTTP.
- Кэш
Сервер может инструктировать прокси и клиенты: что и как долго кэшировать. Клиент может инструктировать прокси промежуточных кэшей игнорировать хранимые документы. - Ослабление ограничений источника
Для предотвращения шпионских и других, нарушающих приватность, вторжений, веб-браузер обчеспечивает строгое разделение между веб-сайтами. Только страницы из того же источника могут получить доступ к информации на веб-странице. Хотя такие ограничение нагружают сервер, заголовки HTTP могут ослабить строгое разделение на стороне сервера, позволяя документу стать частью информации с различных доменов (по причинам безопасности). - Аутентификация
Некоторые страницы доступны только специальным пользователям. Базовая аутентификация может предоставляться через HTTP, либо через использование заголовкаWWW-Authenticateи подобных ему, либо с помощью настройки спецсессии, используя куки. - Прокси и тунелирование
Серверы и/или клиенты часто располагаются в интранете, и скрывают свои истинные IP-адреса от других. HTTP запросы идут через прокси для пересечения этого сетевого барьера. Не все прокси — HTTP прокси. SOCKS-протокол, например, оперирует на более низком уровне. Другие, как, например, ftp, могут быть обработаны этими прокси. - Сессии
Использование HTTP кук позволяет связать запрос с состоянием на сервере. Это создает сессию, хотя ядро HTTP — протокол без состояния. Это полезно не только для корзин в интернет-магазинах, но также для любых сайтов, позволяющих пользователю настроить выход.
HTTP поток
Когда клиент хочет взаимодействовать с сервером, являясь конечным сервером или промежуточным прокси, он выполняет следующие шаги:
- Открытие TCP соединения: TCP-соедиенение будет использоваться для отправки запроса или запросов, и получения ответа. Клиент может открыть новое соединение, переиспользовать существующее, или открыть несколько TCP-соединений к серверу.
- Отправка HTTP-сообщения: HTTP-собщения (до HTTP/2) — человеко-читаемо. Начиная с HTTP/2, простые сообщения инкапсилуруются во фреймы, делая невозможным их чтения напрямую, но принципиально остаются такими же.
GET / HTTP/1.1 Host: developer.mozilla.org Accept-Language: fr - Читает ответ от сервера:
HTTP/1.1 200 OK Date: Sat, 09 Oct 2010 14:28:02 GMT Server: Apache Last-Modified: Tue, 01 Dec 2009 20:18:22 GMT ETag: "51142bc1-7449-479b075b2891b" Accept-Ranges: bytes Content-Length: 29769 Content-Type: text/html <!DOCTYPE html... (here comes the 29769 bytes of the requested web page) - Закрывает или переиспользует соединение для дальнейщих запросов.
Если активирован HTTP-конвеер, несколько запросов могут быть отправлены без ожидания получения первого ответа целиком. HTTP-конвеер тяжело внедряется в существующие сети, где старые куски ПО сосуществуют с современными версиями. HTTP-конвеер был заменен в HTTP/2 на более надежные мультиплексивные запросы во фрейме.
HTTP сообщения
HTTP/1.1 и более ранние HTTP сообщения человеко-читаемы. В версии HTTP/2 эти сообщения встроены в новую бинарную структуру, фрейм, позволяющий оптимизации, такие как компрессия заголовков и мультиплексирование. Даже если часть оригинального HTTP сообщения отправлена в этой версии HTTP, семантика каждого сообщения не изменяется и клиент воссоздаёт (виртуально) оригинальный HTTP-запрос. Это также полезно для понимания HTTP/2 сообщений в формате HTTP/1.1.
Существует два типа HTTP сообщений, запросы и ответы, каждый в своем формате.
Запросы
Примеры HTTP запросов:
Запросы содержат следующие элементы:
- HTTP-метод, обычно глагол подобно
GET,POSTили существительное, какOPTIONSилиHEAD, определяющее операцию, которую клиент хочет выполнить. Обычно, клиент хочет получить ресурс (используяGET) или передать значения HTML-формы (используяPOST), хотя другие операция могут быть необходимы в других случаях. - Путь к ресурсу: URL ресурсы лишены элементов, которые очевидны из контекста, например без protocol (
http://), domain (здесьdeveloper.mozilla.org), или TCP port (здесь80). - Версию HTTP-протокола.
- Заголовки (опционально), предоставляюшие дополнительную информацию для сервера.
- Или тело, для некоторых методов, таких как
POST, которое содержит отправленный ресурс.
Ответы
Примеры ответов:
Ответы содержат следующие элементы:
- Версию HTTP-протокола.
- HTTP код состояния, сообщающий об успешности запроса или причине неудачи.
- Сообщение состояния — краткое описание кода состояния.
- HTTP заголовки, подобно заголовкам в запросах.
- Опционально: тело, содержащее пересылаемый ресурс.
Вывод
HTTP — легкий в использовании расширяемый протокол. Структура клиент-сервера, вместе со способностью к простому добавлению заголовков, позволяет HTTP продвигаться вместе с расширяющимися возможностями Сети.
Хотя HTTP/2 добавляет некоторую сложность, встраивая HTTP сообщения во фреймы для улучшения производительности, базовая структура сообщений осталась с HTTP/1.0. Сессионый поток остается простым, позволяя исследовать и отлаживать с простым монитором HTTP-сообщений.
Путь к HTTP/2 / Habr
От переводчика: перед вами краткий обзор протокола HTTP и его истории — от версии 0.9 к версии 2.
HTTP — протокол, пронизывающий веб. Знать его обязан каждый веб-разработчик. Понимание работы HTTP поможет вам делать более качественные веб-приложения.
В этой статье мы обсудим, что такое HTTP, и как он стал именно таким, каким мы видим его сегодня.
Что такое HTTP?
Итак, рассмотрим для начала, что же такое HTTP? HTTP — протокол прикладного уровня, реализованный поверх протокола TCP/IP. HTTP определяет, как взаимодействуют между собой клиент и сервер, как запрашивается и передаётся контент по интернету. Под протоколом прикладного уровня я понимаю, что это лишь абстракция, стандартизующая, как узлы сети (клиенты и серверы) взаимодействуют друг с другом. Сам HTTP зависит от протокола TCP/IP, позволяющего посылать и отправлять запросы между клиентом и сервером. По умолчанию используется 80 порт TCP, но могут использоваться и другие. HTTPS, например, использует 443 порт.
HTTP/0.9 — первый стандарт (1991)
Первой задокументированной версией HTTP стал HTTP/0.9, выпущенный в 1991 году. Это был самый простой протокол на свете, c одним-единственным методом — GET. Если клиенту нужно было получить какую-либо страницу на сервере, он делал запрос:
GET /index.htmlА от сервера приходил примерно такой ответ:
(response body)
(connection closed)Вот и всё. Сервер получает запрос, посылает HTML в ответ, и как только весь контент будет передан, закрывает соединение. В HTTP/0.9 нет никаких заголовков, единственный метод — GET, а ответ приходит в HTML.
Итак, HTTP/0.9 стал первым шагом во всей дальнейшей истории.
HTTP/1.0 — 1996
В отличие от HTTP/0.9, спроектированного только для HTML-ответов, HTTP/1.0 справляется и с другими форматами: изображения, видео, текст и другие типы контента. В него добавлены новые методы (такие, как POST и HEAD). Изменился формат запросов/ответов. К запросам и ответам добавились HTTP-заголовки. Добавлены коды состояний, чтобы различать разные ответы сервера. Введена поддержка кодировок. Добавлены составные типы данных (multi-part types), авторизация, кэширование, различные кодировки контента и ещё многое другое.
Вот так выглядели простые запрос и ответ по протоколу HTTP/1.0:
GET / HTTP/1.0
Host: kamranahmed.info
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5)
Accept: */*Помимо запроса клиент посылал персональную информацию, требуемый тип ответа и т.д. В HTTP/0.9 клиент не послал бы такую информацию, поскольку заголовков попросту не существовало.
Пример ответа на подобный запрос:
HTTP/1.0 200 OK
Content-Type: text/plain
Content-Length: 137582
Expires: Thu, 05 Dec 1997 16:00:00 GMT
Last-Modified: Wed, 5 August 1996 15:55:28 GMT
Server: Apache 0.84
(response body)
(connection closed)В начале ответа стоит HTTP/1.0 (HTTP и номер версии), затем код состояния — 200, затем — описание кода состояния.
В новой версии заголовки запросов и ответов были закодированы в ASCII (HTTP/0.9 весь был закодирован в ASCII), а вот тело ответа могло быть любого контентного типа — изображением, видео, HTML, обычным текстом и т. п. Теперь сервер мог послать любой тип контента клиенту, поэтому словосочетание «Hyper Text» в аббревиатуре HTTP стало искажением. HMTP, или Hypermedia Transfer Protocol, пожалуй, стало бы более уместным названием, но все к тому времени уже привыкли к HTTP.
Один из главных недостатков HTTP/1.0 — то, что вы не можете послать несколько запросов во время одного соединения. Если клиенту надо что-либо получить от сервера, ему нужно открыть новое TCP-соединение, и, как только запрос будет выполнен, это соединение закроется. Для каждого следующего запроса нужно создавать новое соединение.
Почему это плохо? Давайте предположим, что вы открываете страницу, содержащую 10 изображений, 5 файлов стилей и 5 JavaScript файлов. В общей сложности при запросе к этой странице вам нужно получить 20 ресурсов — а это значит, что серверу придётся создать 20 отдельных соединений. Такое число соединений значительно сказывается на производительности, поскольку каждое новое TCP-соединение требует «тройного рукопожатия», за которым следует медленный старт.
Тройное рукопожатие
«Тройное рукопожатие» — это обмен последовательностью пакетов между клиентом и сервером, позволяющий установить TCP-соединение для начала передачи данных.
- SYN — Клиент генерирует случайное число, например, x, и отправляет его на сервер.
- SYN ACK — Сервер подтверждает этот запрос, посылая обратно пакет ACK, состоящий из случайного числа, выбранного сервером (допустим, y), и числа x + 1, где x — число, пришедшее от клиента.
- ACK — клиент увеличивает число y, полученное от сервера и посылает y + 1 на сервер.
Примечание переводчика: SYN — синхронизация номеров последовательности, (англ. Synchronize sequence numbers). ACK — поле «Номер подтверждения» задействовано (англ. Acknowledgement field is significant).
Только после завершения тройного рукопожатия начинается передача данных между клиентом и сервером. Стоит заметить, что клиент может посылать данные сразу же после отправки последнего ACK-пакета, однако сервер всё равно ожидает ACK-пакет, чтобы выполнить запрос.
Тем не менее, некоторые реализации HTTP/1.0 старались преодолеть эту проблему, добавив новый заголовок Connection: keep-alive, который говорил бы серверу «Эй, дружище, не закрывай это соединение, оно нам ещё пригодится». Однако эта возможность не была широко распространена, поэтому проблема оставалась актуальна.
Помимо того, что HTTP — протокол без установления соединения, в нём также не предусмотрена поддержка состояний. Иными словами, сервер не хранит информации о клиенте, поэтому каждому запросу приходится включать в себя всю необходимую серверу информацию, без учёта прошлых запросов. И это только подливает масла в огонь: помимо огромного числа соединений, которые открывает клиент, он также посылает повторяющиеся данные, излишне перегружая сеть.
HTTP/1.1 – 1999
Прошло 3 года со времён HTTP/1.0, и в 1999 вышла новая версия протокола — HTTP/1.1, включающая множество улучшений:
- Новые HTTP-методы — PUT, PATCH, HEAD, OPTIONS, DELETE.
- Идентификация хостов. В HTTP/1.0 заголовок Host не был обязательным, а HTTP/1.1 сделал его таковым.
- Постоянные соединения. Как говорилось выше, в HTTP/1.0 одно соединение обрабатывало лишь один запрос и после этого сразу закрывалось, что вызывало серьёзные проблемы с производительностью и проблемы с задержками. В HTTP/1.1 появились постоянные соединения, т.е. соединения, которые по умолчанию не закрывались, оставаясь открытыми для нескольких последовательных запросов. Чтобы закрыть соединение, нужно было при запросе добавить заголовок Connection: close. Клиенты обычно посылали этот заголовок в последнем запросе к серверу, чтобы безопасно закрыть соединение.
- Потоковая передача данных, при которой клиент может в рамках соединения посылать множественные запросы к серверу, не ожидая ответов, а сервер посылает ответы в той же последовательности, в которой получены запросы. Но, вы можете спросить, как же клиент узнает, когда закончится один ответ и начнётся другой? Для разрешения этой задачи устанавливается заголовок Content-Length, с помощью которого клиент определяет, где заканчивается один ответ и можно ожидать следующий.
Замечу, что для того, чтобы ощутить пользу постоянных соединений или потоковой передачи данных, заголовок Content-Length должен быть доступен в ответе. Это позволит клиенту понять, когда завершится передача и можно будет отправить следующий запрос (в случае обычных последовательных запросов) или начинать ожидание следующего ответа (в случае потоковой передачи).
Но в таком подходе по-прежнему оставались проблемы. Что, если данные динамичны, и сервер не может перед отправкой узнать длину контента? Получается, в этом случае мы не можем пользоваться постоянными соединениями? Чтобы разрешить эту задачу, HTTP/1.1 ввёл сhunked encoding — механизм разбиения информации на небольшие части (chunks) и их передачу.
- Chunked Transfers если контент строится динамически и сервер в начале передачи не может определить Content-Length, он начинает отсылать контент частями, друг за другом, и добавлять Content-Length к каждой передаваемой части. Когда все части отправлены, посылается пустой пакет с заголовком Content-Length, установленным в 0, сигнализируя клиенту, что передача завершена. Чтобы сказать клиенту, что передача будет вестись по частям, сервер добавляет заголовок Transfer-Encoding: chunked.
- В отличие от базовой аутентификации в HTTP/1.0, в HTTP/1.1 добавились дайджест-аутентификация и прокси-аутентификация.
- Кэширование.
- Диапазоны байт (byte ranges).
- Кодировки
- Согласование содержимого (content negotiation).
- Клиентские куки.
- Улучшенная поддержка сжатия.
- И другие…
Особенности HTTP/1.1 — отдельная тема для разговора, и в этой статье я не буду задерживаться на ней надолго. Вы можете найти огромное количество материалов по этой теме. Рекомендую к прочтению Key differences between HTTP/1.0 and HTTP/1.1 и, для супергероев, ссылку на RFC.
HTTP/1.1 появился в 1999 и пробыл стандартом долгие годы. И, хотя он и был намного лучше своего предшественника, со временем начал устаревать. Веб постоянно растёт и меняется, и с каждым днём загрузка веб-страниц требует всё больших ресурсов. Сегодня стандартной веб-странице приходится открывать более 30 соединений. Вы скажете: «Но… ведь… в HTTP/1.1 существуют постоянные соединения…». Однако, дело в том, что HTTP/1.1 поддерживает лишь одно внешнее соединение в любой момент времени. HTTP/1.1 пытался исправить это потоковой передачей данных, однако это не решало задачу полностью. Возникала проблема блокировки начала очереди (head-of-line blocking) — когда медленный или большой запрос блокировал все последующие (ведь они выполнялись в порядке очереди). Чтобы преодолеть эти недостатки HTTP/1.1, разработчики изобретали обходные пути. Примером тому служат спрайты, закодированные в CSS изображения, конкатенация CSS и JS файлов, доменное шардирование и другие.
SPDY — 2009
Google пошёл дальше и стал экспериментировать с альтернативными протоколами, поставив цель сделать веб быстрее и улучшить уровень безопасности за счёт уменьшения времени задержек веб-страниц. В 2009 году они представили протокол SPDY.
Казалось, что если мы будем продолжать увеличивать пропускную способность сети, увеличится её производительность. Однако выяснилось, что с определенного момента рост пропускной способности перестаёт влиять на производительность. С другой стороны, если оперировать величиной задержки, то есть уменьшать время отклика, прирост производительности будет постоянным. В этом и заключалась основная идея SPDY.
Следует пояснить, в чём разница: время задержки — величина, показывающая, сколько времени займёт передача данных от отправителя к получателю (в миллисекундах), а пропускная способность — количество данных, переданных в секунду (бит в секунду).
SPDY включал в себя мультиплексирование, сжатие, приоритизацию, безопасность и т.д… Я не хочу погружаться в рассказ про SPDY, поскольку в следующем разделе мы разберём типичные свойства HTTP/2, а HTTP/2 многое перенял от SPDY.
SPDY не старался заменить собой HTTP. Он был переходным уровнем над HTTP, существовавшим на прикладном уровне, и изменял запрос перед его отправкой по проводам. Он начал становиться стандартом дефакто, и большинство браузеров стали его поддерживать.
В 2015 в Google решили, что не должно быть двух конкурирующих стандартов, и объединили SPDY с HTTP, дав начало HTTP/2.
HTTP/2 — 2015
Думаю, вы уже убедились, что нам нужна новая версия HTTP-протокола. HTTP/2 разрабатывался для транспортировки контента с низким временем задержки. Главные отличия от HTTP/1.1:
- бинарный вместо текстового
- мультиплексирование — передача нескольких асинхронных HTTP-запросов по одному TCP-соединению
- сжатие заголовков методом HPACK
- Server Push — несколько ответов на один запрос
- приоритизация запросов
- безопасность
1. Бинарный протокол
HTTP/2 пытается решить проблему выросшей задержки, существовавшую в HTTP/1.x, переходом на бинарный формат. Бинарные сообщения быстрее разбираются автоматически, но, в отличие от HTTP/1.x, не удобны для чтения человеком. Основные составляющие HTTP/2 — фреймы (Frames) и потоки (Streams).
Фреймы и потоки.
Сейчас HTTP-сообщения состоят из одного или более фреймов. Для метаданных используется фрейм HEADERS, для основных данных — фрейм DATA, и ещё существуют другие типы фреймов (RST_STREAM, SETTINGS, PRIORITY и т.д.), с которыми можно ознакомиться в спецификации HTTP/2.
Каждый запрос и ответ HTTP/2 получает уникальный идентификатор потока и разделяется на фреймы. Фреймы представляют собой просто бинарные части данных. Коллекция фреймов называется потоком (Stream). Каждый фрейм содержит идентификатор потока, показывающий, к какому потоку он принадлежит, а также каждый фрейм содержит общий заголовок. Также, помимо того, что идентификатор потока уникален, стоит упомянуть, что каждый клиентский запрос использует нечётные id, а ответ от сервера — чётные.
Помимо HEADERS и DATA, стоит упомянуть ещё и RST_STREAM — специальный тип фреймов, использующийся для прерывания потоков. Клиент может послать этот фрейм серверу, сигнализируя, что данный поток ему больше не нужен. В HTTP/1.1 единственным способом заставить сервер перестать посылать ответы было закрытие соединения, что увеличивало время задержки, ведь нужно было открыть новое соединение для любых дальнейших запросов. А в HTTP/2 клиент может отправить RST_STREAM и перестать получать определённый поток. При этом соединение останется открытым, что позволяет работать остальным потокам.
2. Мультиплексирование
Поскольку HTTP/2 является бинарным протоколом, использующим для запросов и ответов фреймы и потоки, как было упомянуто выше, все потоки посылаются в едином TCP-соединении, без создания дополнительных. Сервер, в свою очередь, отвечает аналогичным асинхронным образом. Это значит, что ответ не имеет порядка, и клиент использует идентификатор потока, чтобы понять, к какому потоку принадлежит тот или иной пакет. Это решает проблему блокировки начала очереди (head-of-line blocking) — клиенту не придётся простаивать, ожидая обработки длинного запроса, ведь во время ожидания могут обрабатываться остальные запросы.
3. Сжатие заголовков методом HPACK
Это было частью отдельного RFC, специально нацеленного на оптимизацию отправляемых заголовков. В основе лежало то, что если мы постоянного обращаемся к серверу из одного и того же клиента, то в заголовках раз за разом посылается огромное количество повторяющихся данных. А иногда к этому добавляются ещё и куки, раздувающие размер заголовков, что снижает пропускную способность сети и увеличивает время задержки. Чтобы решить эту проблему, в HTTP/2 появилось сжатие заголовков.
В отличие от запросов и ответов, заголовки не сжимаются в gzip или подобные форматы. Для сжатия используется иной механизм — литеральные значения сжимаются по алгоритму Хаффмана, а клиент и сервер поддерживают единую таблицу заголовков. Повторяющиеся заголовки (например, user agent) опускаются при повторных запросах и ссылаются на их позицию в таблице заголовков.
Раз уж зашла речь о заголовках, позвольте добавить, что они не отличаются от HTTP/1.1, за исключением того, что добавилось несколько псевдозаголовков, таких как :method, :scheme, :host, :path и прочие.
4. Server Push
Server push — ещё одна потрясающая особенность HTTP/2. Сервер, зная, что клиент собирается запросить определённый ресурс, может отправить его, не дожидаясь запроса. Вот, например, когда это будет полезно: браузер загружает веб-страницу, он разбирает её и находит, какой ещё контент необходимо загрузить с сервера, а затем отправляет соответствующие запросы.
Server push позволяет серверу снизить количество дополнительных запросов. Если он знает, что клиент собирается запросить данные, он сразу их посылает. Сервер отправляет специальный фрейм PUSH_PROMISE, говоря клиенту: «Эй, дружище, сейчас я тебе отправлю вот этот ресурс. И не надо лишний раз беспокоить.» Фрейм PUSH_PROMISE связан с потоком, который вызвал отправку push-а, и содержит идентификатор потока, по которому сервер отправит нужный ресурс.
5. Приоритизация запросов
Клиент может назначить приоритет потоку, добавив информацию о приоритете во фрейм HEADERS, которым открывается поток. В любое другое время клиент может отправить фрейм PRIORITY, меняющий приоритет потока.
Если никакой информации о приоритете не указанно, сервер обрабатывает запрос асинхронно, т.е. без какого-либо порядка. Если приоритет назначен, то, на основе информации о приоритетах, сервер принимает решение, сколько ресурсов выделяется для обработки того или иного потока.
6. Безопасность
Насчёт того, должна ли безопасность (передача поверх протокола TLS) быть обязательной для HTTP/2 или нет, развилась обширная дискуссия. В конце концов было решено не делать это обязательным. Однако большинство производителей браузеров заявило, что они будут поддерживать HTTP/2 только тогда, когда он будет использоваться поверх TLS. Таким образом, хотя спецификация не требует шифрования для HTTP/2, оно всё равно станет обязательным по умолчанию. При этом HTTP/2, реализованный поверх TLS, накладывает некоторые ограничения: необходим TLS версии 1.2 или выше, есть ограничения на минимальный размер ключей, требуются эфемерные ключи и так далее.
Заключение
HTTP/2 уже здесь, и уже обошёл SPDY в поддержке, которая постепенно растёт. Для всех, кому интересно узнать больше, вот ссылка на спецификацию и ссылка на демо, показывающее преимущества скорости HTTP/2.
HTTP/2 может многое предложить для увеличения производительности, и, похоже, самое время начать его использовать.
Оригинал: Journey to HTTP/2, автор Kamran Ahmed.
Перевод: Андрей Алексеев, редактура: Анатолий Тутов, Jabher, Игорь Пелехань, Наталья Ёркина, Тимофей Маринин, Чайка Чурсина, Яна Крикливая.
HTTP — протокол уровня приложений / Habr
Данная статья является переводом первой статьи из цикла статей о протоколе HTTP с сайта opera.com.Пересоздал её, чтобы тип статьи стал переводом.
Введение
В Бутане, когда люди знакомятся, они обычно приветствуют друг друга словами «Твоё тело чувствует себя хорошо?». В Японии они могут кланяться, в зависимости от обстановки. В Омане мужчины обычно целуют друг друга в нос, после рукопожатия. В Камбодже и Таиланде они обычно соединяют ладони, как при молитве. Это все протоколы общения, простая последовательность кодов, которая имеется значение и готовит обе стороны к обмену информацией.
В Интернете есть очень эффективный протокол прикладного уровня, который готовит компьютеры к обмену информацией: Hypertext Transfer Protocol, или HTTP. HTTP — протокол прикладного уровня поверх коммуникационного протокола TCP/IP. HTTP часто упускается из вида при изучении веб-дизайна и веб-разработки, что является ошибкой: понимание его помогает определить лучший способ взаимодействия с пользователями, достичь лучшей производительности сайта и создает эффективный инструмент для управления информацией в сети Интернет.
Это первая статья из серии статей, целью которой является научить основам HTTP и эффективному его использованию. В этой статье мы увидим на каком этапе HTTP работает в механизме Интернет.
Что такое коммуникационный протокол?
До того, как углубиться в специфику, давайте рассмотрим базовый коммуникационный сценарий. Чтобы обмениваться информацией, обеим сторонам (которые могут быть программным обеспечением, устройством, людьми, и т.д.) необходимо установить:
- синтакс (формат данных и программного кода)
- семантика (управление информацией и обработка ошибок)
- тайминг (согласование по времени и последовательности)
Когда два человека встречаются, они пользуются коммуникационным протоколом: например, в Японии при встрече с кем-либо человек делает специфическое действие с телом. Одно из таких действий — поклон, который является синтаксисом, используемым для взаимодействия. В японской традиции жест «поклон» (и многие другие) ассоциируется с семантикой приветствия кого-либо. В итоге, когда один человек кланяется другому, устанавливается цепочка событий между этими двумя людьми в определенном тайминге.
Онлайновый коммуникационный протокол состоит из тех же элементов. Синтаксисом будет последовательность символов, как ключевые слова, которые мы используем для написания протокола. Семантика — значение, ассоциированное с каждым из этих слов и, в заключении, тайминг — последовательность в которой две или более сущности обмениваются этими словами.
Где HTTP вклинивается в механизм?
Сам HTTP работает поверх остальных протоколов. Во время соединения к веб-сайту, например к www.example.org, пользовательский агент использует семейство протоколов TCP/IP. Модель TCP/IP, спроектированная в 1970, состоит из 4 уровней:
- Уровень сетевого доступа, описывающий доступ к физическому устройству (т.е. использующее сетевую карту)
- Межсетевой уровень, описывающий размещения данных в дейтаграмме и роутинг данных — как они пакуются (IP)
- Транспортный уровень, описывающий способ, которым доставляются данные из исходной точки к финальному получателю (TCP, UDP)
- Прикладной уровень, описывающий значение или формат передаваемых сообщений (HTTP)
HTTP — протокол прикладного уровня, который находится над коммуникационным протоколом. Это важно иметь ввиду. Разделение модели на независимые уровни помогает развивать части платформы, без необходимости переписывать всё. Например, TCP, протокол транспортного уровня, можно развивать, без необходимости модифицировать HTTP, протокол прикладного уровня. В первых статьях про HTTP мы уделим внимание разделению уровней, как это сделано в TCP/IP модели. HTTP предназначен для обмена информацией двумя частями программного обеспечения посредством HTTP сообщений. То, как мы формируем и проектируем эти сообщения, имеет значение как для клиента (браузер, например), так и для сервера (веб-сайт) и посредников (прокси-сервер).
Давайте доберемся до сервера
Порт 80 — порт по умолчанию для соединения к веб-серверам. Мы можем сами попробовать подключиться к веб-серверу, используя командную строку. Откройте командную строку и попробуйте открыть соединение к www.opera.com на порт 80 используя следующую команду:
telnet www.opera.com 80Вы должны получить вывод наподобие:
Trying 195.189.143.147...
Connected to front.opera.com.
Escape character is '^]'.
Connection closed by foreign host.Мы видим, что терминал пытается установить соединение с сервером, расположенным по адресу 195.189.143.147. Если мы больше ничего не будем делать, сервер сам закроет соединение. Можно использовать и другие порты и даже другой коммуникационный протокол, но эти — самые общепринятые.
Давайте поговорим немного об HTTP
Давай опять попробуем соединиться с сервером. Введите следующее сообщение в вашей командной строке:
telnet www.opera.com 80Как только соединение установится, введите следующее HTTP сообщение быстро (до того, как соединение автоматически закроется), потом нажмите Enter дважды:
GET / HTTP/1.1
Host: www.opera.comЭто сообщение означает:
- GET: Что мы хотим получить информацию.
- /: Что информация, которую мы хотим получить находится в корне сайта.
- HTTP/1.1: Что мы используем HTTP версии 1.1.
- Host: Мы пытаемся обратиться к определенному сайту.
- www.opera.com: имя сайта — www.opera.com.
Теперь настает очередь сервера отвечать. Вы должны увидеть в окне терминала содержимое сайта, начиная с этих строк:
HTTP/1.1 200 OK
Date: Wed, 23 Nov 2011 19:41:37 GMT
Server: Apache
Content-Type: text/html; charset=utf-8
Set-Cookie: language=none; path=/; domain=www.opera.com; expires=Thu, 25-Aug-2011 19:41:38 GMT
Set-Cookie: language=en; path=/; domain=.opera.com; expires=Sat, 20-Nov-2021 19:41:38 GMT
Vary: Accept-Encoding
Transfer-Encoding: chunked
<!DOCTYPE html>
<html lang="en">
…
Тут сервер отвечает: «Я использую HTTP версии 1.1. Ваш запрос выполнен успешно, поэтому я отвечаю кодом 200». Строка Ok необязательна и присутствует для объяснения людям, что этот код означает людям — в данном случае, что всё хорошо и наш запрос был успешно обработан. Далее, серия HTTP заголовков отправляется, чтобы объяснить что это за сообщение и как его следует понимать. В итоге, содержимое страницы, расположенной в корне сайта добавляется к ответу начиная со строки . Список ключевых слов HTTP и кодов ответа будут описаны в следующих статьях.
Резюме
Мы общались с веб-сервером, используя протокол HTTP — это максимально просто! Мы отправили сообщение (абсолютно так же, как будто написали письмо) и получили ответ, что наше сообщение было понято. В следующий раз мы детально рассмотрим, что значат некоторые из этих заголовков и как они могут быть использованы.