Социальная сеть — Википедия
Социальная сеть — онлайн-платформа, которую люди используют для общения, создания социальных отношений с другими людьми, которые имеют схожие интересы или офлайн-связи.
Помимо перечисленных социальных сетей имеются следующие типы ресурсов в формате Веб 2.0:
- Социальные закладки (англ. social bookmarking). Некоторые веб-сайты позволяют пользователям предоставлять в распоряжение других список закладок или популярных веб-сайтов. Такие сайты также могут использоваться для поиска пользователей с общими интересами. Пример: Delicious.
- Социальные каталоги (англ. social cataloging) напоминают социальные закладки, но ориентированы на использование в академической сфере, позволяя пользователям работать с базами данных цитат из научных статей. Примеры: Academic Search Premier, LexisNexis, Academic University, CiteULike, Connotea.
- Социальные библиотеки представляют собой приложения, позволяющие посетителям оставлять ссылки на их коллекции, книги, аудиозаписи и т. п., доступные другим. Предусмотрена поддержка системы рекомендаций, рейтингов и т. п. Примеры: discogs.com, IMDb.com.
- Социальные медиахранилища — сервисы для совместного хранения медиафайлов. Их можно классифицировать по типу файлов размещаемых на этих серверах.
- Специализированные социальные сети. Объединяют людей по определённым критериям (например, возраст, пол, вероисповедание, определённые увлечения и т. д.).
- Сервисы для совместной работы с документами.
- Геосоциальные сети позволяют налаживать социальные связи на основании географического положения пользователя. При этом используются различные инструменты геолокации (например, GPS или гибридные системы типа технологии AlterGeo), которые дают возможность определять текущее местонахождение того или иного пользователя и соотносить его позицию в пространстве с расположением различных мест и людей вокруг.
Русский писатель, философ и общественный деятель XIX века Владимир Одоевский, живший с 1803 по 1869 год, в своём незаконченном утопическом романе «4338-й год», написанном в 1837 году, предсказал появление современных блогов и Интернета в целом. В нём сказано, что «между знакомыми домами устроены магнетические телеграфы, посредством которых живущие на далёком расстоянии разговаривают друг с другом», а также о «домашних газетах», издающихся «во многих домах, особенно между теми, которые имеют большие знакомства
Предтечей соцсетей стала электронная доска объявлений, первую из них, под названием CBBS, создал сотрудник IBM У. Кристенсен (англ.)русск. в 1978 году[4]. Уже в 1983 году в мире насчитывалось 800 электронных досок, а в 1988 — 5000[5].
Популярность в Интернете социальные сети начали завоёвывать в 1995 году, с появлением американского портала Classmates.com. Проект оказался весьма успешным, что в следующие несколько лет спровоцировало появление не одного десятка аналогичных сервисов. Но официальным началом бума социальных сетей принято считать 2003—2004 года, когда в США были запущены LinkedIn, MySpace и Facebook
Социальные сети являются мощным инструментом маркетинговых исследований, поскольку пользователи добровольно публикуют информацию о себе, своих взглядах, интересах, предпочтениях и так далее. Ввиду этого рекламодатели могут весьма чётко определять, каких именно пользователей заинтересует их объявление, и направить свои рекламные объявления конкретным пользователям, в зависимости от информации в их профилях (возраст, пол, место жительства и прочее). Такой тип рекламы получил название
Объём рынка рекламы в социальных сетях неуклонно растёт. В 2007 году, по оценкам аналитической компании eMarketer, он достиг отметки в 1,225 млрд долларов. При составлении отчёта экспертами eMarketer учитывались все виды рекламы, размещённой в социальных сетях, включая медийную, контекстную, аудио и видеорекламу, а также затраты на маркетинговые проекты, в которых маркетологи создают профили для своих товаров и брендов в социальных сетях. Кроме того, в прогнозах впервые учитываются расходы на создание виджетов и приложений. В 2011 году доходы социальных сетей от рекламы превысили 5 миллиардов долларов
Используя рекламу в социальных сетях, можно работать с группами пользователей, объединённых по таким параметрам, как:
- интересы;
- возраст;
- география;
- пол;
- социальное положение;
- уровень дохода;
- марка используемого мобильного устройства (Apple, Samsung)
- и т. п.
Другим способом привлечения клиентов через социальные сети является создание компаниями сообществ в социальных сетях. Такие сообщества позволяют доносить новую информацию до пользователей, которых вероятнее всего заинтересует продукция или услуги компании.
Социальные сети могут использоваться не только в качестве инструментов связей с общественностью и прямого маркетинга, но и в качестве каналов связи, предназначенных для очень специфической аудитории с влиятельными лицами в социальных сетях и личностями социальных сетей, а также в качестве эффективных инструментов привлечения клиентов.[8]
Многие люди не понимают, что информация, размещённая ими в социальных сетях, может быть найдена и использована кем угодно, не обязательно с благими намерениями. Информацию о человеке в социальных сетей могут найти их работодатели[9], родственники, сборщики долгов, преступники и другие заинтересованные лица. Судебные приставы иногда используют социальные сети, чтобы найти неплательщиков или получить сведения об их имуществе
Некоторые работодатели запрещают пользоваться социальными сетями — не только ради экономии, но и чтобы воспрепятствовать утечке информации[11].
Также пользователи соцсетей могут столкнуться с травлей, критикой, «нелестными отзывами» и необоснованными слухами[12].
Известен случай проявления психосоматических расстройств на почве зависимости от общения в социальных сетях — в Белграде пользователь Снежана Павло́вич (Snezhana Pavlović) попала в психиатрическую клинику после того, как её заметка в социальной сети «Facebook» не вызвала интереса среди её друзей. Врачи клиники назвали этот случай «синдром Снежаны», объясняя поведение пациентки как обычный стресс от неудовлетворённости социальной потребности индивидуума в современном мире
Тема рисков использования социальных сетей была освещена в множестве научных работ, в том числе:
- Д. Бойд на основании материалов опросов в 16 штатах США сделала вывод о двух основных «страхах», вызываемых социальными сетями: сексуальные домогательства и конфиденциальность информации.
- Контент-анализ периодической печати в Дании позволил М. Ларсен составить список наиболее часто упоминаемых проблем в связи с социальными сетями, куда входят: сексуальное насилие и педофилия, запугивание и преследование, угрозы и насилие, распространение националистических идей.
- К. Фукс в ходе онлайн-опроса немецких и австрийских студентов получил следующий список рисков: конфиденциальность данных, распространение спама, возможность потери личной информации, создание негативного имиджа, интернет-зависимость.
- С. В. Бондаренко на материале исследования виртуальных сетевых сообществ юга России сделал вывод о наличии следующих форм проявления девиантного поведения: хакерство, нарушение режима секретности, диффамация, кибертерроризм, компьютерная педофилия.
- Опрос, проведённый на портале ГУ-ВШЭ, показал, что по мнению респондентов, сети «затягивают» и отнимают слишком много времени, вытесняют реальное общение, обеспечивают «избыточность общения и информации».
- В работе «Аутопойезис социальных сетей в интернет-пространстве» было проиллюстрировано, как социальные сети распределяют, интегрируют и задают рамки психологических рекурсий; они расходуют смоделированный психикой код посредством перенесения всё большего числа элементов частной жизни во всеобщее тотальное поле взаимодействий
Некоторые СМИ утверждают, что в соцсетях действуют так называемые группы смерти, которые пропагандируют суицид и могут довести детей до самоубийства[16][17]. В 2016-м году Роспотребнадзор заявил, что более трети материалов, описывающих способы добровольного ухода из жизни и агитирующих к ней собрано в социальной сети «ВКонтакте»[18]. С 7 июня 2017 года в России действует закон об уголовной ответственности за создание «групп смерти» в интернете предусматривающий до 6 лет лишения свободы[19]. Создатель социальной сети «ВКонтакте» Павел Валерьевич Дуров в своём интервью DLD Conference упоминал про проблемы интернет-троллинга и обещал решить их, создав новую социальную сеть «LiveOnce», используя уже готовые серверные решения и протоколы «Telegram»
- ↑ Профессиональные социальные сети обеспечивают работой каждого третьего пользователя, Открытые системы (12 марта 2013). Дата обращения 26 февраля 2017.
- ↑ Корпоративная социальная сеть, Журнал IT-Manager: № 03/2014. Дата обращения 26 февраля 2017.
- ↑ Интернет и блоги предсказал Владимир Одоевский в 1837 году — Лента.ру, 3.10.2005
- ↑ Catherine D. Marcum. History of Social Networking // Social Networking as a Criminal Enterprise. CRC Press, 2014. (англ.) С. 4.
- ↑ Management Review of EPA Bulletin Board Systems. EPA, 1990. (англ.) С. 8.
- ↑ Ефимов, 2015, pp. 68—69, 72-73.
- ↑ Реклама в соцсетях переживает «золотой век» (7 октября 2011). Дата обращения 26 февраля 2017.
- ↑ Constantinides E.; Lorenzo C.; Gómez M.A. Social Media: A New Frontier for Retailers?. — European Retail Research, 2008. — С. 22. — ISBN 978-3-8349-8099-1.
- ↑ «МЮ» уволил скаута за расистские высказывания в соцсетях
- ↑ Банки ловят должников через «Одноклассников», «В контакте» и «Мой круг» // NEWSru.com
- ↑ Московским полицейским запретили пользоваться соцсетями и мессенджерами (неопр.) (недоступная ссылка). Дата обращения 19 апреля 2016. Архивировано 6 сентября 2016 года.
- ↑ «Столько злости, желчи и зависти». Победительницы конкурса «Мисс Россия» о травле в соцсетях
- ↑ Россия в социальных сетях: какой ущерб от виртуальной жизни? (неопр.). ТАСС. Дата обращения 26 февраля 2017.
- ↑ Ефимов, Кузнецов, 2011.
- ↑ Лавренчук, 2011.
- ↑ Группы смерти (18+) (неопр.).
- ↑ Пять главных вопросов к материалу «Новой газеты» о подростковых суицидах (неопр.).
- ↑ Треть пропагандирующих суицид интернет-страниц пришлась на «ВКонтакте» (неопр.). Lenta.ru (16 мая 2016). Дата обращения 26 февраля 2017.
- ↑ Путин подписал закон об уголовной ответственности за создание «групп смерти» // Интерфакс, 07.06. 2017
- ↑ Pavel Durov (неопр.). DLD Conference. Дата обращения 16 мая 2018.
- Лавренчук Е. А.. Аутопойезис социальных сетей в интернет-пространстве : диссертация. — М., 2011.
- Boyd, D. and Ellison, N. Social Network Sites: Definition, History, and Scholarship (англ.) // Journal of Computer-Mediated Communication. — 2007. — Vol. 13, no. 1. — P. 210—230. — ISSN 10836101. — DOI:10.1111/j.1083-6101.2007.00393.x.
- Ефимов Е. Г., Кузнецов А. А.. Виды кризисного потенциала социальных сетей как региональных социально-экономических систем. — Волгоград : ФГОУ ВПО ВАГС, 2011. — С. 144—145. — ISBN 978-5-7786-0419-3.
- Наталия Ермолова. Продвижение бизнеса в социальных сетях Facebook, Twitter, Google+. — М.: Альпина Паблишер, 2013. — 357 с. — ISBN 978-5-9614-2280-1.
- Социальные сети и виртуальные сетевые сообщества / отв. ред. Верченов Л. Н., Ефременко Д. В., Тищенко В. И. — М.: ИНИОН РАН, 2013. — 360 с. — ISBN 978-5-248-00644-1.
- Ефимов Е.Г. Социальные Интернет-сети (методология и практика исследования). — Волгоград: Волгоградское научное издательство, 2015. — 168 с. — ISBN 978-5-00072-109-4.
- Buchheit, Paul (founder of FriendFeed). An essay on the features that seem to define the social network aspect of a product.
- Alemán, Ana M. Martínez; Wartman, Katherine Lynk, «Online social networking on campus: understanding what matters in student culture», New York and London : Routledge, 1st edition, 2009. ISBN 0-415-99019-X
- Barham, Nick, Disconnected: Why our kids are turning their backs on everything we thought we knew, 1st ed., Ebury Press, 2004. ISBN 0-09-189586-3
- Baron, Naomi S., Always on : language in an online and mobile world, Oxford ; New York : Oxford University Press, 2008. ISBN 978-0-19-531305-5
- Cao, Jinwei, Kamile Asli Basoglu, Hong Sheng, and Paul Benjamin Lowry (2015). «A systematic review of social networking research in information systems, » (Communications of the Association for Information Systems vol. 36(1)).
- Cockrell, Cathy, «Plumbing the mysterious practices of ‘digital youth’: In first public report from a ‘seminal’ study, UC Berkeley scholars shed light on kids’ use of Web 2.0 tools», UC Berkeley News, University of California, Berkeley, NewsCenter, April 28, 2008
- Davis, Donald Carrington, «MySpace Isn’t Your Space: Expanding the Fair Credit Reporting Act to Ensure Accountability and Fairness in Employer Searches of Online Social Networking Services», 16 Kan. J.L. & Pub. Pol’y 237 (2007).
- Else, Liz; Turkle, Sherry. «Living online: I’ll have to ask my friends», New Scientist, issue 2569, September 20, 2006. (interview)
- Glaser, Mark, Your Guide to Social Networking Online, PBS MediaShift, August 2007
- Powers, William, Hamlet’s Blackberry : a practical philosophy for building a good life in the digital age, 1st ed., New York : Harper, 2010. ISBN 978-0-06-168716-7
- C. Infant Louis Richards, «Advanced Techniques to overcome privacy issues and SNS threats» PDF October 2011
- Robert W. Gehl, Reverse Engineering Social Media: Software, Culture, and Political Economy in New Media Capitalism, Philadelphia: Temple University Press 2014, ISBN 978-1-43991-035-1.
- Sharples, Mike; Graber, Rebecca; Harrison, Colin; Logan, Kit. E-Safety and Web2.0 for children aged 11–16 (неопр.) // Journal of Computer-Assisted Learning. — 2009. — Т. 25. — С. 70—84. — DOI:10.1111/j.1365-2729.2008.00304.x.
Поисковая система — Википедия
Поиск информации во Всемирной паутине был трудной и не самой приятной задачей, но с прорывом в технологии поисковых систем в конце 1990-х годов осуществлять поиск стало намного удобнейПоиско́вая систе́ма (англ. search engine) — это компьютерная система, предназначенная для поиска информации[источник не указан 375 дней]. Одно из наиболее известных применений поисковых систем — веб-сервисы для поиска текстовой или графической информации во Всемирной паутине. Существуют также системы, способные искать файлы на FTP-серверах, товары в интернет-магазинах, информацию в группах новостей Usenet.
Для поиска информации с помощью поисковой системы пользователь формулирует поисковый запрос[1]. Работа поисковой системы заключается в том, чтобы по запросу пользователя найти документы, содержащие либо указанные ключевые слова, либо слова, как-либо связанные с ключевыми словами[2]. При этом поисковая система генерирует страницу результатов поиска. Такая поисковая выдача может содержать различные типы результатов, например: веб-страницы, изображения, аудиофайлы. Некоторые поисковые системы также извлекают информацию из подходящих баз данных и каталогов ресурсов в Интернете.
Поисковая система тем лучше, чем больше документов, релевантных запросу пользователя, она будет возвращать. Результаты поиска могут становиться менее релевантными из-за особенностей алгоритмов (см. «Пузырь фильтров»[⇨]) или вследствие человеческого фактора[⇨]. По состоянию на 2015 год самой популярной поисковой системой в мире является Google, однако есть страны, где пользователи отдали предпочтение другим поисковикам. Так, например, в России «Яндекс» обгоняет Google больше, чем на 10 %[⇨].
По методам поиска и обслуживания разделяют четыре типа поисковых систем: системы, использующие поисковых роботов, системы, управляемые человеком, гибридные системы и мета-системы[⇨]. В архитектуру поисковой системы обычно входят:
- поисковый робот, собирающий информацию с сайтов сети Интернет или из других документов,
- индексатор, обеспечивающий быстрый поиск по накопленной информации, и
- поисковик — графический интерфейс для работы пользователя[⇨].
На раннем этапе развития сети Интернет Тим Бернерс-Ли поддерживал список веб-серверов, размещённый на сайте ЦЕРН[3]. Сайтов становилось всё больше, и поддерживать вручную такой список становилось всё сложнее. На сайте NCSA был специальный раздел «Что нового!» (англ. What’s New!)[4], где публиковали ссылки на новые сайты.
Первой компьютерной программой для поиска в Интернете была программа Арчи[en] (англ. archie — архив без буквы «в»). Она была создана в 1990 году Аланом Эмтэджем (Alan Emtage), Биллом Хиланом (Bill Heelan) и Дж. Питером Дойчем (J. Peter Deutsch), студентами, изучающими информатику в университете Макгилла в Монреале. Программа скачивала списки всех файлов со всех доступных анонимных FTP-серверов и строила базу данных, в которой можно было выполнять поиск по именам файлов. Однако, программа Арчи не индексировала содержимое этих файлов, так как объём данных был настолько мал, что всё можно было легко найти вручную.
Развитие и распространение сетевого протокола Gopher, придуманного в 1991 году Марком Маккэхилом (Mark McCahill) в университете Миннесоты, привело к созданию двух новых поисковых программ, Veronica[en] и Jughead[en]. Как и Арчи, они искали имена файлов и заголовки, сохранённые в индексных системах Gopher. Veronica (англ. Very Easy Rodent-Oriented Net-wide Index to Computerized Archives) позволяла выполнять поиск по ключевым словам большинства заголовков меню Gopher во всех списках Gopher. Программа Jughead (англ. Jonzy’s Universal Gopher Hierarchy Excavation And Display) извлекала информацию о меню от определённых Gopher-серверов. Хотя название поисковика Арчи не имело отношения к циклу комиксов «Арчи»[en], тем не менее Veronica и Jughead — персонажи этих комиксов.
К лету 1993 года ещё не было ни одной системы для поиска в вебе, хотя вручную поддерживались многочисленные специализированные каталоги. Оскар Нирштрасс (Oscar Nierstrasz) в Женевском университете написал ряд сценариев на Perl, которые периодически копировали эти страницы и переписывали их в стандартный формат. Это стало основой для W3Catalog, первой примитивной поисковой системы сети, запущенной 2 сентября 1993 года[5].
Вероятно, первым поисковым роботом, написанным на языке Perl, был «World Wide Web Wanderer» — бот Мэтью Грэя (Matthew Gray) из Массачусетского технологического института в июне 1993 года. Этот робот создавал поисковый индекс «Wandex». Цель робота Wanderer состояла в том, чтобы измерить размер всемирной паутины и найти все веб-страницы, содержащие слова из запроса. В 1993 году появилась и вторая поисковая система «Aliweb». Aliweb не использовала поискового робота, но вместо этого ожидала уведомлений от администраторов веб-сайтов о наличии на их сайтах индексного файла в определённом формате.
JumpStation[en], [6] созданный в декабре 1993 года Джонатаном Флетчером, искал веб-страницы и строил их индексы с помощью поискового робота, и использовал веб-форму в качестве интерфейса для формулирования поисковых запросов. Это был первый инструмент поиска в Интернете, который сочетал три важнейших функции поисковой системы (проверка, индексация и собственно поиск). Из-за ограниченности ресурсов компьютеров того времени индексация и, следовательно, поиск были ограничены только названиями и заголовками веб-страниц, найденных поисковым роботом.
Первой полнотекстовой индексирующей ресурсы при помощи робота («craweler-based») поисковой системой, стала система «WebCrawler»[en], запущенная в 1994 году. В отличие от своих предшественниц, она позволяла пользователям искать по любым словам, расположенным на любой веб-странице — с тех пор это стало стандартом для большинства поисковых систем. Кроме того, это был первый поисковик, получивший широкое распространение. В 1994 году была запущена система «Lycos», разработанная в Университете Карнеги-Меллон и ставшая серьёзным коммерческим предприятием.
Вскоре появилось множество других конкурирующих поисковых машин, таких как: «Magellan»[en], «Excite», «Infoseek»[en], «Inktomi»[en], «Northern Light»[en] и «AltaVista». В некотором смысле они конкурировали с популярными интернет-каталогами, такими как «Yahoo!». Но поисковые возможности каталогов ограничивались поиском по самим каталогам, а не по текстам веб-страниц. Позже каталоги объединялись или снабжались поисковыми роботами с целью улучшения поиска.
В 1996 году компания Netscape хотела заключить эксклюзивную сделку с одной из поисковых систем, сделав её поисковой системой по умолчанию на веб-браузере Netscape. Это вызвало настолько большой интерес, что Netscape заключила контракт сразу с пятью крупнейшими поисковыми системами (Yahoo!, Magellan, Lycos, Infoseek и Excite). За 5 млн долларов США в год они предлагались по очереди на поисковой странице Netscape[7][8].
Поисковые системы участвовали в «Пузыре доткомов» конца 1990-х[9]. Несколько компаний эффектно вышли на рынок, получив рекордную прибыль во время их первичного публичного предложения. Некоторые отказались от рынка общедоступных поисковых движков и стали работать только с корпоративным сектором, например, Northern Light[en].
Google взял на вооружение идею продажи ключевых слов в 1998 году, тогда это была маленькая компания, обеспечивавшая работу поисковой системы по адресу goto.com[en]. Этот шаг ознаменовал для поисковых систем переход от соревнований друг с другом к одному из самых выгодных коммерческих предприятий в Интернете[10]. Поисковые системы стали продавать первые места в результатах поиска отдельным компаниям.
Поисковая система Google занимает видное положение с начала 2000-х[11]. Компания добилась высокого положения благодаря хорошим результатам поиска с помощью алгоритма PageRank. Алгоритм был представлен общественности в статье «The Anatomy of Search Engine», написанной Сергеем Брином и Ларри Пейджем, основателями Google[12]. Этот итеративный алгоритм ранжирует веб-страницы, основываясь на оценке количества гиперссылок на веб-страницу в предположении, что на «хорошие» и «важные» страницы ссылаются больше, чем на другие. Интерфейс Google выдержан в спартанском стиле, где нет ничего лишнего, в отличие от многих своих конкурентов, которые встраивали поисковую систему в веб-портал. Поисковая система Google стала настолько популярной, что появились подражающие ей системы, например, Mystery Seeker[en](тайный поисковик).
К 2000 году Yahoo! осуществлял поиск на основе системы Inktomi. Yahoo! в 2002 году купил Inktomi, а в 2003 году купил Overture, которому принадлежали AlltheWeb[en] и AltaVista. Затем Yahoo! работал на основе поисковой системы Google вплоть до 2004 года, пока не запустил, наконец, свой собственный поисковик на основе всех купленных ранее технологий.
Фирма Microsoft впервые запустила поисковую систему Microsoft Network Search (MSN Search) осенью 1998 года, используя результаты поиска от Inktomi. Совсем скоро в начале 1999 года сайт начал отображать выдачу Looksmart[en], смешанную с результатами Inktomi. Недолго (в 1999 году) MSN search использовал результаты поиска от AltaVista. В 2004 году фирма Microsoft начала переход к собственной поисковой технологии с использованием собственного поискового робота — msnbot[en]. После проведения ребрендинга компанией Microsoft 1 июня 2009 года была запущена поисковая система Bing. 29 июля 2009 Yahoo! и Microsoft подписали соглашение, согласно которому Yahoo! Search[en] работал на основе технологии Microsoft Bing. На момент 2015 года союз Bing и Yahoo! дал первые настоящие плоды. Теперь Bing занимает 20,1 % рынка, а Yahoo! 12,7 %, что в общем занимает 32,60 % от общего рынка поисковых систем в США по данным из разных источников.
Поиск информации на русском языке[править | править код]
В 1996 году был реализован поиск с учётом русской морфологии на поисковой машине Altavista и запущены оригинальные российские поисковые машины Рамблер и Апорт. 23 сентября 1997 года была открыта поисковая машина Яндекс. 22 мая 2014 года компанией Ростелеком была открыта национальная поисковая машина Спутник, которая на момент 2015 года находится в стадии бета-тестировании. 22 апреля 2015 года был открыт новый сервис Спутник. Дети специально для детей с повышенной безопасностью.
Большую популярность получили методы кластерного анализа и поиска по метаданным. Из международных машин такого плана наибольшую известность получила «Clusty»[en] компании Vivisimo[en]. В 2005 году в России при поддержке МГУ запущен поисковик «Нигма», поддерживающий автоматическую кластеризацию. В 2006 году открылась российская метамашина Quintura, предлагающая визуальную кластеризацию в виде облака тегов. «Нигма» тоже экспериментировала[13] с визуальной кластеризацией.
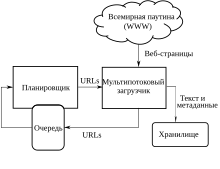 Высокоуровневая архитектура стандартного краулера
Высокоуровневая архитектура стандартного краулераОсновные составляющие поисковой системы: поисковый робот, индексатор, поисковик[14].
Как правило, системы работают поэтапно. Сначала поисковый робот получает контент, затем индексатор генерирует доступный для поиска индекс, и наконец, поисковик обеспечивает функциональность для поиска индексируемых данных. Чтобы обновить поисковую систему, этот цикл индексации выполняется повторно[14].
Поисковые системы работают, храня информацию о многих веб-страницах, которые они получают из HTML-страниц. Поисковый робот или «краулер» (англ. Crawler) — программа, которая автоматически проходит по всем ссылкам, найденным на странице, и выделяет их. Краулер, основываясь на ссылках или исходя из заранее заданного списка адресов, осуществляет поиск новых документов, ещё не известных поисковой системе. Владелец сайта может исключить определённые страницы при помощи robots.txt, используя который можно запретить индексацию файлов, страниц или каталогов сайта.
Поисковая система анализирует содержание каждой страницы для дальнейшего индексирования. Слова могут быть извлечены из заголовков, текста страницы или специальных полей — метатегов. Индексатор — это модуль, который анализирует страницу, предварительно разбив её на части, применяя собственные лексические и морфологические алгоритмы. Все элементы веб-страницы вычленяются и анализируются отдельно. Данные о веб-страницах хранятся в индексной базе данных для использования в последующих запросах. Индекс позволяет быстро находить информацию по запросу пользователя[15].
Ряд поисковых систем, подобных Google, хранят исходную страницу целиком или её часть, так называемый кэш, а также различную информацию о веб-странице. Другие системы, подобные системе AltaVista, хранят каждое слово каждой найденной страницы. Использование кэша помогает ускорить извлечение информации с уже посещённых страниц[15]. Кэшированные страницы всегда содержат тот текст, который пользователь задал в поисковом запросе. Это может быть полезно в том случае, когда веб-страница обновилась, то есть уже не содержит текст запроса пользователя, а страница в кэше ещё старая[15]. Эта ситуация связана с потерей ссылок (англ. linkrot[en]) и дружественным по отношению к пользователю (юзабилити) подходом Google. Это предполагает выдачу из кэша коротких фрагментов текста, содержащих текст запроса. Действует принцип наименьшего удивления, пользователь обычно ожидает увидеть искомые слова в текстах полученных страниц (User expectations[en]). Кроме того, что использование кэшированных страниц ускоряет поиск, страницы в кэше могут содержать такую информацию, которая уже нигде более не доступна.
Поисковик работает с выходными файлами, полученными от индексатора. Поисковик принимает пользовательские запросы, обрабатывает их при помощи индекса и возвращает результаты поиска[14].
Когда пользователь вводит запрос в поисковую систему (обычно при помощи ключевых слов), система проверяет свой индекс и выдаёт список наиболее подходящих веб-страниц (отсортированный по какому-либо критерию), обычно с краткой аннотацией, содержащей заголовок документа и иногда части текста[15]. Поисковый индекс строится по специальной методике на основе информации, извлечённой из веб-страниц[11]. С 2007 года поисковик Google позволяет искать с учётом времени создания искомых документов (вызов меню «Инструменты поиска» и указание временного диапазона).
Большинство поисковых систем поддерживает использование в запросах булевых операторов И, ИЛИ, НЕ, что позволяет уточнить или расширить список искомых ключевых слов. При этом система будет искать слова или фразы точно так, как было введено. В некоторых поисковых системах есть возможность приближённого поиска[en], в этом случае пользователи расширяют область поиска, указывая расстояние до ключевых слов[15]. Есть также концептуальный поиск[en], при котором используется статистический анализ употребления искомых слов и фраз в текстах веб-страниц. Эти системы позволяют составлять запросы на естественном языке. Примером такой поисковой системы является сайт ask com.
Полезность поисковой системы зависит от релевантности найденных ею страниц. Хоть миллионы веб-страниц и могут включать некое слово или фразу, но одни из них могут быть более релевантны, популярны или авторитетны, чем другие. Большинство поисковых систем использует методы ранжирования, чтобы вывести в начало списка «лучшие» результаты. Поисковые системы решают, какие страницы более релевантны, и в каком порядке должны быть показаны результаты, по-разному[15]. Методы поиска, как и сам Интернет со временем меняются. Так появились два основных типа поисковых систем: системы предопределённых и иерархически упорядоченных ключевых слов и системы, в которых генерируется инвертированный индекс на основе анализа текста.
Большинство поисковых систем являются коммерческими предприятиями, которые получают прибыль за счёт рекламы, в некоторых поисковиках можно купить за отдельную плату первые места в выдаче для заданных ключевых слов. Те поисковые системы, которые не берут денег за порядок выдачи результатов, зарабатывают на контекстной рекламе, при этом рекламные сообщения соответствуют запросу пользователя. Такая реклама выводится на странице со списком результатов поиска, и поисковики зарабатывают при каждом клике пользователя на рекламные сообщения.
Существует четыре типа поисковых систем: с поисковыми роботами, управляемые человеком, гибридные и мета-системы[16].
- системы, использующие поисковые роботы
- Состоят из трёх частей: краулер («бот», «робот» или «паук»), индекс и программное обеспечение поисковой системы. Краулер нужен для обхода сети и создания списков веб-страниц. Индекс — большой архив копий веб-страниц. Цель программного обеспечения — оценивать результаты поиска. Благодаря тому, что поисковый робот в этом механизме постоянно исследует сеть, информация в большей степени актуальна. Большинство современных поисковых систем являются системами данного типа.
- Эти поисковые системы получают списки веб-страниц. Каталог содержит адрес, заголовок и краткое описание сайта. Каталог ресурсов ищет результаты только из описаний страницы, представленных ему веб-мастерами. Достоинство каталогов в том, что все ресурсы проверяются вручную, следовательно, и качество контента будет лучше по сравнению с результатами, полученными системой первого типа автоматически. Но есть и недостаток — обновление данных каталогов выполняется вручную и может существенно отставать от реального положения дел. Ранжирование страниц не может мгновенно меняться. В качестве примеров таких систем можно привести каталог Yahoo[en], dmoz и Galaxy.
- гибридные системы
- Такие поисковые системы, как Yahoo, Google, MSN, сочетают в себе функции систем, использующие поисковых роботов, и систем, управляемых человеком.
- Метапоисковые системы объединяют и ранжируют результаты сразу нескольких поисковиков. Эти поисковые системы были полезны, когда у каждой поисковой системы был уникальный индекс, и поисковые системы были менее «умными». Поскольку сейчас поиск намного улучшился, потребность в них уменьшилась. Примеры: MetaCrawler[en] и MSN Search.
Google — самая популярная поисковая система в мире с долей на рынке 69,24 %. Bing занимает вторую позицию, его доля 12,26 %[17].
Самые популярные поисковые системы в мире[18]:
| Поисковая система | Доля рынка в июле 2014 | Доля рынка в октябре 2014 | Доля рынка в сентябре 2017 |
|---|---|---|---|
| 68,69 % | 58,01 % | 69,24 % | |
| Bing | 17,17 % | 29,06 % | 12,26 % |
| Baidu | 6,22 % | 8,01 % | 6,48 % |
| Yahoo! | 6,74 % | 4,01 % | 5,19 % |
| AOL | 0,13 % | 0,21 % | 1,11 % |
| Excite | 0,22 % | 0,00 % | 0,00 % |
| Ask | 0,13 % | 0,10 % | 0,24 % |
Азия[править | править код]
В восточноазиатских странах и в России Google — не самая популярная поисковая система. В Китае, например, более популярна поисковая система Soso.
В Южной Корее поисковым порталом собственной разработки Naver пользуется около 70 % жителей[19]Yahoo! Japan и Yahoo! Taiwan — самые популярные системы для поиска в Японии и Тайване соответственно[20].
Россия и русскоязычные поисковые системы[править | править код]
Яндексом пользуются 53,3 % пользователей в России (Google — 42,9 %)[21].
Согласно данным LiveInternet в декабре 2017 года об охвате русскоязычных поисковых запросов[22]:
- Всеязычные:
- Англоязычные и международные:
- Русскоязычные — большинство «русскоязычных» поисковых систем индексируют и ищут тексты на многих языках — украинском, белорусском, английском, татарском и других. Отличаются же они от «всеязычных» систем, индексирующих все документы подряд, тем, что, в основном, индексируют ресурсы, расположенные в доменных зонах, где доминирует русский язык, или другими способами ограничивают своих роботов русскоязычными сайтами.
Некоторые из поисковых систем используют внешние алгоритмы поиска.
Количественные данные поисковой системы Google[править | править код]
Число пользователей Интернета и поисковых систем и требований пользователей к этим системам постоянно растёт. Для увеличений скорости поиска нужной информации крупные поисковые системы содержат большое количество серверов. Сервера обычно группируют в серверные центры (дата-центры). У популярных поисковых систем серверные центры разбросаны по всему миру[23].
В октябре 2012 года Google запустила проект «Где живёт Интернет», где пользователям предоставляется возможность познакомиться с центрами обработки данных этой компании[24].
О работе дата-центров поисковой системе Google известно следующее[23]:
- Суммарная мощность всех дата-центров Google, по состоянию на 2011 год, оценивалась в 220 МВт.
- Когда в 2008 году Google планировала открыть в Орегоне новый комплекс, состоящий из трёх зданий общей площадью 6,5 млн м², в журнале Harper’s Magazine подсчитали, что такой большой комплекс потребляет свыше 100 МВт электроэнергии, что сравнимо с потреблением энергии города с населением 300 000 человек.
- Ориентировочное число серверов Google в 2012 году — 1 000 000.
- Расходы Google на дата-центры составили в 2006 году — $1,9 млрд, а в 2007 году — $2,4 млрд.
Размер всемирной паутины, проиндексированной Google на декабрь 2014 года, составляет примерно 4,36 миллиарда страниц[25].
Поисковые системы, учитывающие религиозные запреты[править | править код]
Глобальное распространение Интернета и увеличение популярности электронных устройств в арабском и мусульманском мире, в частности, в странах Ближнего Востока и Индийского субконтинента, способствовало развитию локальных поисковых систем, учитывающих исламские традиции. Такие поисковые системы содержат специальные фильтры, которые помогают пользователям не попадать на запрещённые сайты, например, сайты с порнографией, и позволяют им пользоваться только теми сайтами, содержимое которых не противоречит исламской вере.
Незадолго до мусульманского месяца Рамадан, в июле 2013 года, миру был представлен Halalgoogling[en] — система, выдающая пользователям только халяльные «правильные» ссылки[26], фильтруя результаты поиска, полученные от других поисковых систем, таких как Google и Bing. Двумя годами ранее, в сентябре 2011 года, был запущен поисковый движок I’mHalal, предназначенный для обслуживания пользователей Ближнего Востока. Однако этот поисковый сервис пришлось вскоре закрыть, по сообщению владельца, из-за отсутствия финансирования[27].
Отсутствие инвестиций и медленный темп распространения технологий в мусульманском мире препятствовали прогрессу и мешали успеху серьёзного исламского поисковика. Очевиден провал огромных инвестиций в веб-проекты мусульманского образа жизни, одним из которых был Muxlim[en]. Он получил миллионы долларов от инвесторов, таких как Rite Internet Ventures, и теперь — в соответствии с последним сообщением от I’mHalal перед его закрытием — выступает с сомнительной идеей о том, что «следующий Facebook или Google могут появиться только в странах Ближнего Востока, если вы поддержите нашу блестящую молодёжь»[28].
Тем не менее исламские эксперты в области Интернета в течение многих лет занимаются определением того, что соответствует или не соответствует шариату, и классифицируют веб-сайты как «халяль» или «харам». Все бывшие и настоящие исламские поисковые системы представляют собой просто специальным образом проиндексированный набор данных либо это главные поисковые системы, такие как Google, Yahoo и Bing, с определённой системой фильтрации, использующейся для того, чтобы пользователи не могли получить доступ к харам-сайтам, таким как сайты о наготе, ЛГБТ, азартных играх и каким-либо другим, тематика которых считается антиисламской[28].
Среди других религиозно-ориентированных поисковых систем распространёнными являются Jewogle — еврейская версия Google и SeekFind.org — христианский сайт, включающий в себя фильтры, оберегающие пользователей от контента, который может подорвать или ослабить их веру[29].
Персональные результаты и пузыри фильтров[править | править код]
Многие поисковые системы, такие как Google и Bing, используют алгоритмы выборочного угадывания того, какую информацию пользователь хотел бы увидеть, основываясь на его прошлых действиях в системе. В результате, веб-сайты показывают только ту информацию, которая согласуется с прошлыми интересами пользователя. Этот эффект получил название «пузырь фильтров»[30].
Всё это ведёт к тому, что пользователи получают намного меньше противоречащей своей точке зрения информации и становятся интеллектуально изолированными в своём собственном «информационном пузыре». Таким образом, «эффект пузыря» может иметь негативные последствия для формирования гражданского мнения[31].
Несмотря на то, что поисковые системы запрограммированы, чтобы оценивать веб-сайты на основе некоторой комбинации их популярности и релевантности, в реальности экспериментальные исследования указывают на то, что различные политические, экономические и социальные факторы оказывают влияние на поисковую выдачу[32][33].
Такая предвзятость может быть прямым результатом экономических и коммерческих процессов: компании, которые рекламируются в поисковой системе, могут стать более популярными в результатах обычного поиска в ней. Удаление результатов поиска, не соответствующих местным законам, является примером влияния политических процессов. Например, Google не будет отображать некоторые неонацистские веб-сайты во Франции и Германии, где отрицание Холокоста незаконно[34].
Предвзятость может также быть следствием социальных процессов, поскольку алгоритмы поисковых систем часто разрабатываются, чтобы исключить неформатные точки зрения в пользу более «популярных» результатов[35]. Алгоритмы индексации главных поисковых систем отдают приоритет американским сайтам[33].
Поисковая бомба — один из примеров попытки управления результатами поиска по политическим, социальным или коммерческим причинам.
- ↑ Chu & Rosenthal, 1996, p. 129.
- ↑ Tarakeswar & Kavitha, 2011, p. 29.
- ↑ World-Wide Web Servers.
- ↑ What’s New.
- ↑ Oscar Nierstrasz.
- ↑ Archive of NCSA.
- ↑ Yahoo! And Netscape.
- ↑ Netscape, 1996.
- ↑ The dynamics of competition, 2001.
- ↑ Intro to Computer Science.
- ↑ 1 2 Google`s history.
- ↑ Брин и Пейдж, p. 3.
- ↑ Nigma.
- ↑ 1 2 3 Risvik & Michelsen, 2002, p. 290.
- ↑ 1 2 3 4 5 6 Knowledge Management, 2011.
- ↑ Tarakeswar & Kavitha, 2011, p. 29.
- ↑ NMS.
- ↑ Статистика.
- ↑ Naver.
- ↑ Age of Internet Empires.
- ↑ LiveInternet.
- ↑ Liveinternet
- ↑ 1 2 Antula.
- ↑ Where the Internet lives.
- ↑ World wide web size.
- ↑ Islam.
- ↑ I’mHalal
- ↑ 1 2 Halalblog
- ↑ ChristianNews.
- ↑ Pariser, 2011.
- ↑ Auralist, 2012, p. 13.
- ↑ Segev, 2010.
Веб-страница — Википедия
Материал из Википедии — свободной энциклопедии
Текущая версия страницы пока не проверялась опытными участниками и может значительно отличаться от версии, проверенной 25 августа 2018; проверки требуют 3 правки. Текущая версия страницы пока не проверялась опытными участниками и может значительно отличаться от версии, проверенной 25 августа 2018; проверки требуют 3 правки. Скриншот веб-страницы английской Википедии
Скриншот веб-страницы английской ВикипедииВеб-страница (англ. Web page) — документ или информационный ресурс Всемирной паутины, доступ к которому осуществляется с помощью веб-браузера. Типичная веб-страница представляет собой текстовый файл в формате HTML, который может содержать ссылки на файлы в других форматах (текст, графические изображения, видео, аудио, мультимедиа, апплеты, прикладные программы, базы данных, веб-службы и прочее), а также гиперссылки для быстрого перехода на другие веб-страницы или доступа к ссылочным файлам. Многие современные браузеры позволяют просмотр содержания ссылочных файлов непосредственно на веб-странице, содержащей ссылку на данный файл. Современные браузеры также позволяют прямой просмотр содержания файлов определённых форматов, в отрыве от веб-страницы, которая на них ссылается.
Информационно значимое содержимое веб-страницы обычно называется контентом (от англ. content — «содержание»).
Несколько веб-страниц, объединённых общей темой и дизайном, а также связанных между собой ссылками, образуют веб-сайт. При этом образующие веб-сайт страницы могут находиться на одном или нескольких веб-серверах, которые могут располагаться в одном дата-центре или удалённо друг от друга, зачастую в разных странах.
Динамическая страница — веб-страница, сгенерированная программно, в отличие от статичной страницы, которая является просто файлом, лежащим на сервере. Сервер генерирует HTML-код динамической страницы для обработки браузером или другим агентом пользователя.
Динамические страницы обычно обрабатывают и выводят информацию из базы данных. Наиболее популярные на данный момент технологии для генерации динамических страниц:
Персональная интернет-страница — веб-страница, представляющая (официально или нет) личность той или иной персоны или персонажа.
Предназначена для представления информации о человеке, его хобби, интересах, увлечениях для пользователей всемирной паутины.
Обсуждение категории:Интернет — Википедия
Материал из Википедии — свободной энциклопедии
Категория Интернет дважды входит в родительскую категорию Категория:Телекоммуникации.
- Телекоммуникации -> Интернет
- Телекоммуникации -> Компьютерные сети -> Компьютерные сети по типу -> Интернет
В англо-вики немного другая проблема, ещё хуже — зацикливание категории:
- Telecommunications -> Telecommunications infrastructure -> Computer networks -> Internet
- Telecommunications -> Telecommunications infrastructure -> Computer networks -> Internet -> Computer networks by scale -> Wide area networks -> Internet
- Networks -> Computer networks и т.д.
Чё делать, исправлять или так оставить? ~Нирваньчик~ øβς 21:35, 26 ноября 2011 (UTC)
- Исходя из определений: (КС) «Компьютерная сеть (вычислительная сеть, сеть передачи данных) — система связи компьютеров и/или компьютерного оборудования (серверы, маршрутизаторы и другое оборудование)», (И) «Интернет — всемирная система объединённых компьютерных сетей, построенная на использовании протокола IP и маршрутизации пакетов данных», И — подмножество КС. Типов (категория «Компьютерные сети по типу») — масса (см. Компьютерная сеть#Классификация). Определения для Телекоммуникация нет, только редирект на Электросвязь. Вывод: Даём определение для Телекоммуникация и становится понятна иерархия понятий. Fractaler 10:36, 28 ноября 2011 (UTC)
- Понятно. С англовики я кстати напутал. Прошу прощения. У них иерархия тоже с двойным вхождением, но Internet не входит в телекоммуникации напрямую, а Computer networks входит (в Telecommunications infrastructure).
- Computer networks -> Internet
- Computer networks -> Computer networks by scale -> Wide area networks -> Internet
- При этом Internet входит ещё в несколько каких-то категорий. Если сделать так:
- Телекоммуникации -> Компьютерные сети -> Интернет
- Телекоммуникации -> Компьютерные сети -> Компьютерные сети по типу -> Интернет
- то у нас будет как у них. Но надо сделать как правильно, а чтобы как правильно, вы уже сказали что нужно, и этого у нас нет
 Что-ж, будем искать. ~Нирваньчик~ øβς 12:32, 28 ноября 2011 (UTC)
Что-ж, будем искать. ~Нирваньчик~ øβς 12:32, 28 ноября 2011 (UTC)
- Понятно. С англовики я кстати напутал. Прошу прощения. У них иерархия тоже с двойным вхождением, но Internet не входит в телекоммуникации напрямую, а Computer networks входит (в Telecommunications infrastructure).
 Что-ж, будем искать.
Что-ж, будем искать. ~Нирваньчик~ øβς 12:32, 28 ноября 2011 (UTC)
~Нирваньчик~ øβς 12:32, 28 ноября 2011 (UTC)Telecommunication is the extension of communication over a distance. It includes radio, telegraphy, television, telephony, data communication and computer networking — en:Category:Telecommunications . Вот такое определение дано в en-wiki, только без ссылок. Сдаётся мне, что Интернет это подвид/подкатегория компьютерной сети и входит в Телек. только потому что комп. сети туда входят. А вот определение которое я google нашёл на русском:
- «Телекоммуникация — это связь при помощи электронного оборудования такого, как телефоны, компьютерные модемы, спутники и волоконно-оптические кабели. Телекоммуникационные системы включают в себя телекоммуникационные кабели от абонента до местных коммутаторов (местные линии), коммутационные средства, которые обеспечивают коммуникационное соединение с абонентом, с линиями или каналами, которые передают вызовы между коммутаторами и, естественно, абонентом.»
- «Телекоммуникации — это любая передача, источник информации или прием знаков, сигналов, сообщений, изображений и звуков или информации любого вида посредством передачи, радио, визуальных или других электромагнитных систем. ».
Англичане правы, а нам надо исправляться. Я так думаю. Хотя у них определения явно дано шире. ~Нирваньчик~ øβς 12:44, 28 ноября 2011 (UTC)
- Попробуем пока прикинуть. Имеем: процесс (передача информации, т.е. связь) и результат процесса — Интернет. По идее, для связи, т.е., передачи информации (на растояние, не во времени=её сохранения) существует 2 среды — проводная и беспроводная. Для передачи необходимы средства — оборудование, сети, приёмно-передающие устройства/передатчики (устройства-машины, люди) и т.д. Т.о., есть 2 понятия для термина Интернет (нужно будет разделить) — Интернет как сеть/среда (средство распространения информации со своими стандартами, параметрами, историями и т.д. протоколы) и непосредственно всё остальное (всё, что использует эту среду для коммуникаций — люди, машины). Как то примерно так. Fractaler 08:28, 29 ноября 2011 (UTC)
- Телекоммуникации это не только процесс но и средства передачи, это дано в первом определении. Интернет это сеть сетей, или объединение сетей, или группа сетей. Сеть это система связи компьютеров и/или компьютерного оборудования или collection of hardware components and computers. Получается что Интернет состоит из сетей, сети состоят из телекоммуникационного оборудования. Телекоммуник. это не только оборудование но и процесс, более широкое понятие чем Интернет и Компьютерные сети. Интернет и Компьютерные сети это очень близкие понятия. В общем, любая иерархия здесь уместна, даже когда Интернет сразу в трёх категориях, главное чтобы соблюдалось старшинство. Единственное что немного смущает — это то что Интернет и Компьютерные сети находятся как бы в одном ранге, находясь в категории Телекоммуникации. Но и это нормально, если рассматривать К. сети слегка в более в узком смысле (локальные и корпоративные компьютерные сети). Вообще, я поднял этот вопрос в англо-вики тоже. Они сказали что множественное вхождение это нормально, и даже циклы (вхождение категории самой в себя) это нормально. И что структура категорий Википедии — это не дерево а направленный граф. И в основном здесь всё категоризируют по смыслу.
В общем, сейчас категоризация нормальная, но возможны и такие альтернативные варианты
1 вхождение
- Телекоммуникации -> Компьютерные сети -> Компьютерные сети по типу -> Интернет
2 вхождения (более близко к англо-вики)
- Телекоммуникации -> Компьютерные сети -> Интернет
- Телекоммуникации -> Компьютерные сети -> Компьютерные сети по типу -> Интернет
Ещё что меня смущает, это Категория:Компьютерные сети по типу. Домовые сети и Интернет (как глобальная вычислительная сеть) я бы отнёс к Категория:Компьютерные сети по охвату, туда же идут Локальные вычислительные сети и Корпоративные сети. Категория:Домовые сети как категория вообще мне не ясна. Сколько статей сюда можно отнести кроме самой статьи Домовая сеть? Кто её создал? Напрашивается на переименование в Категория:Локальные сети или Категория:Локальные вычислительные сети.
- Можно также ничего не делать а просто переименовать Категория:Компьютерные сети по типу в Категория:Компьютерные сети по типу и охвату~Нирваньчик~ øβς 09:50, 29 ноября 2011 (UTC)
- Похоже, что Категория:Домовые сети имеет право на существование (en:Category:Personal area networks, Персональная сеть) но с другим названием Категория:Персональные сети ~Нирваньчик~ øβς 10:36, 29 ноября 2011 (UTC)
- Если используются только Википедия:Родовые категории, то правильная иерархия понятий структура должна быть только типа Дерево (граф) (видовые категории — просто ссылками/указателями, не как надкатегории). Скорее всего основная проблема с термином Интернет — в его множественности значений (т.е., он 1) Средство — комп. сеть, 2) Всё, что позволяет данная сеть (приём/передача между машинами, людьми). Похоже, нужно уточнять это понятие (сетям — сетевое, кесарю — кесарево) —Fractaler 11:46, 29 ноября 2011 (UTC)
- Если честно, то у на примитивном уровне возникают такие ассоциации на данные термины: при слове компьютерная сеть представляется 10 или 100 компов, соединенных витой парой, и мигающий в углу свитч, а при слове интернет представляются спутники на орбите, урчащие железные ящики где-нибудь в Нью-Тауне (сервера), сайты-сайты-сайты и форумы, и миллоны юзеров за компами и смартфонами. Интернет это библиотека. Интернет это взаимодействие человека с миллионами других людей. Трудно представить себе интернет без www пространства. А комп. сеть, вернемся к ней, это куча железа плюс программы-протоколы за счет которых это железо может взаимодействовать друг с другом. Так что, эта два облака, которые имеют область общего пересечения, но всётаки это разные облака. И текущая категоризация это подтверждает. ~Нирваньчик~ øβς 12:13, 29 ноября 2011 (UTC)
- Спасибо за Википедия:Родовые категории. Ознакомлюсь с текстом и сделаю выводы. ~Нирваньчик~ øβς 12:17, 29 ноября 2011 (UTC)
- Я думаю придерживаться нужно правил, а если их нет, то здравого смысла. В определении Интернета ни слова не сказано о телекоммуникациях, или о какой-либо связи Интернета с телекоммуникациями. Отсюда можно сделать вывод что Интернет отнесен в Телекоммуникации ошибочно. Но ведь те, кто это сделал, так не считали? ~Нирваньчик~ øβς 16:55, 29 ноября 2011 (UTC)
- Пока нет правил, прямо указывающих алгоритм выбора названия категории для статьи или надкатегории, а здравый смысл — понятие относительное. Т.к. определение термина «Интернета» в статье вообще без АИ, то нам даже на него не опереться. Fractaler 14:24, 30 ноября 2011 (UTC)
- Да, действительно. ~Нирваньчик~ øβς 06:23, 1 декабря 2011 (UTC)
Википедия:Марафон/Интернет — Википедия
Материал из Википедии — свободной энциклопедии

Марафон по написанию статей в Википедии на темы, связанные с Интернетом. Призы — билеты на церемонию вручения Премии Рунета, которая состоится 21 ноября 2013 в Москве, и подписка на журнал «Интернет в цифрах» на 2014 год. Марафон проводится с 28 октября по 10 ноября 2013 включительно. Спешите зарегистрироваться!
Для участия необходимо записаться ниже.
| Участник | Статьи | Баллы (заполняют члены жюри) | Примечания |
|---|---|---|---|
| Saint Johann | Dailymotion | 1+1=2 | |
| Niklem | NetEase, Хактивизм, Demand Progress, Zedo, Imgur, AVG Technologies, Годвин, Майк, Цензура Википедии, Интернет-права | 9+1+2=12 | |
| JukoFF | Wikipedia App, BlackBerry World, Sina Corp, Wikipedia Zero Вне зачёта:Список самых посещаемых веб-сайтов | 4+2+1=7 | |
| Сергеев Павел | World Wide Web Foundation, World Wide Web Conference Вне зачёта:Шаблон:Зал славы интернета 2013 | 2+1=3 | |
| DonSimon | Боб Меткалфе | 1 | |
| Biathlon | MacWWW, Пузен, Луи, Андрессен, Марк | 3+1=4 | |
| AndreyIGOSHEV | .онлайн, .сайт | 2+1+1=4 | |
| Heimdall | Закон По • Aliweb • CSNET | 3+1=4 |
Организаторы Марафона[править код]
Организаторами Марафона выступают Российская Ассоциация электронных коммуникаций (РАЭК) и Некоммерческое партнёрство содействия распространению энциклопедических знаний «Викимедиа РУ».
Основные цели и задачи Марафона[править код]
- Сбор, систематизация и сохранение информации энциклопедически значимых материалов об интернет-проектах, деятелях, явлениях и событиях Интернета, либо тесно связанных с Интернетом, а также обеспечение свободного и надёжного доступа к этой информации;
- Привлечение новых авторов статей в русскоязычный раздел Википедии;
- Популяризация свободных лицензий.
Интернет и всё, что с ним связано.
- Старт Марафона: 28 октября 2013 в 0:01 UTC
- Финиш Марафона: 10 ноября 2013 в 23:59 UTC (продолжительность Марафона: 14 полных суток)
- Подведение итогов Марафона и распределение призов: до 12-13 ноября 2013 года.
- К участию в Марафоне допускаются все желающие, владеющие русским языком. Приветствуется участие новичков.
- Для участия необходима регистрация новой или использование уже имеющейся учётной записи на сайте http://ru.wikipedia.org/ . В Настройках необходимо указать контактный электронный адрес и на вкладке «Личные данные» активировать опцию «Разрешить приём электронной почты от других участников».
- Конкурсные статьи должны соответствовать правилам Википедии:
- Размещая свои произведения в проекте, их авторы соглашаются с условиями их использования, а также соглашаются на их безотзывную публикацию по лицензиям Creative Commons Attribution-ShareAlike 3.0 и GFDL. Также авторы соглашаются, что указание гиперссылки на соответствующую страницу или её URL-адреса будет достаточным для выполнения условия атрибуции лицензии Creative Commons.
Марафон проводится в одной номинации:
- Максимальное количество баллов, набранных автором статей на русском языке:
- Не допускается создание статей с использованием автоматических переводчиков, а также утилит предварительной генерации текста («ботозаливки» запрещены).
- Итоги Марафона подводит жюри, состоящее из опытных и активных участников Википедии на русском языке, в чью сферу интересов входит тема Марафона, имеющие опыт как написания статей, так и подобной работы.
- При подведении итогов учитываются как количество так и качество статей, написанных участниками Марафона. Под качеством подразумевается объём и разумная степень иллюстрированности, важность, актуальность темы, полнота раскрытия, степень подкрепления материалов ссылками на авторитетные источники, оформление. Базовое количество баллов за одну зачётную статью — 1. Жюри может поощрить автора качественной статьи 1 или 2 дополнительными баллами.
- Результаты Марафона публикуются на этой странице. Решение жюри окончательно и обжалованию не подлежит.
- Нарушение условий участия в Марафоне (отсутствие регистрации, создание статей с нарушением авторских прав, нарушения других правил проекта) ведёт к дисквалификации участника Марафона.

- Победители, занявшие первые 5 мест, поощряются пригласительными билетами на церемонию вручения Премии Рунета 21 ноября 2013 в Москве, а также почётными дипломами от НП «Викимедиа РУ».
- Участники, занявшие места с 6 по 10, поощряются годовой подпиской на журнал «Интернет в цифрах», а также почётными дипломами от НП «Викимедиа РУ».
Отказ от ответственности[править код]
- Организаторы Марафона не несут ответственности в случае нарушения участниками Марафона авторских прав третьих лиц.
- Организаторы не несут ответственности за возможное удаление из Википедии страниц, созданных участниками Марафона.
Дополнительные контакты[править код]
- Электронный адрес для направления обращений: [email protected].
- Все интересующие вас вопросы можно задать на странице обсуждения Марафона или любому из членов жюри по вики-почте или на личной странице обсуждения.
- Dmitry Rozhkov
- Zoe
- Vladimir Solovjev
- Фил Вечеровский
- Dimetr
Места распределились следующим образом:
1. Niklem — 12 баллов
2. JukoFF — 7 баллов
3-5. AndreyIGOSHEV, Biathlon, Heimdall — по 4 балла.
Эти участники получают приглашение на церемонию вручения Премии Рунета, которая состоится 21 ноября в Москве.
6. Сергеев Павел — 3 балла
7. Saint Johann — 2 балла
8. DonSimon — 1 балл.
Эти три участника поощряются подпиской на журнал «Интернет в цифрах» на 2014 год.
- Подписи членов жюри