Тестируем универсальную распознавалку CAPTCHA — «Хакер»
Содержание статьи
Есть разные способы для обхода CAPTCHA, которыми защищены сайты. Во-первых, существуют специальные сервисы, которые используют дешевый ручной труд и буквально за $1 предлагают решить 1000 капч. В качестве альтернативы можно попробовать написать интеллектуальную систему, которая по определенным алгоритмам будет сама выполнять распознавание. Последнее теперь можно реализовать с помощью специальной утилиты.
Решить CAPTCHA
Распознавание CAPTCHA — задача чаще всего нетривиальная. На изображение необходимо накладывать массу различных фильтров, чтобы убрать искажения и помехи, которыми разработчики желают укрепить стойкость защиты. Зачастую приходится реализовывать обучаемую систему на основе нейронные сетей (это, к слову, не так сложно, как может показаться), чтобы добиться приемлемого результата по автоматизированному решению капч. Чтобы понять, о чем я говорю, лучше поднять архив и прочитать замечательные статьи «Взлом CAPTCHA: теория и практика. Разбираемся, как ломают капчи» и «Подсмотрим и распознаем. Взлом Captcha-фильтров» из #135 и #126 номеров соответственно. Сегодня же я хочу рассказать тебе о разработке TesserCap, которую автор называет универсальной решалкой CAPTCHA. Любопытная штука, как ни крути.
Первый взгляд на TesserCap
Что сделал автор программы? Он посмотрел, как обычно подходят к проблеме автоматизированного решения CAPTCHA и попробовал обобщить этот опыт в одном инструменте. Автор заметил, что для удаления шумов с изображения, то есть решения самой сложной задачи при распознавании капч, чаще всего применяются одни и те же фильтры. Получается, что если реализовать удобный инструмент, позволяющий без сложных математических преобразований накладывать фильтры на изображения, и совместить его с OCR-системой для распознавания текста, то можно получить вполне работоспособную программу. Это, собственно, и сделал Гурсев Сингх Калра из компании McAfee. Зачем это было нужно? Автор утилиты решил таким образом проверить, насколько безопасны капчи крупных ресурсов. Для тестирования были выбраны те интернет-сайты, которые являются самыми посещаемыми по версии известного сервиса статистики. Кандидатами на участие в тестировании стали такие монстры, как Wikipedia, eBay, а также провайдер капч reCaptcha.
Если рассматривать в общих чертах принцип функционирования программы, то он достаточно прост. Исходная капча поступает в систему предварительной обработки изображений, очищающей капчу от всяких шумов и искажений и по конвейеру передающей полученное изображение OCR-системе, которая старается распознать текст на нем. TesserCap имеет интерактивный графический интерфейс и обладает следующими свойствами:
- Имеет универсальную систему предварительной обработки изображений, которую можно настроить для каждой отдельной капчи.
- Включает в себя систему распознавания Tesseract , которая извлекает текст из предварительно проанализированного и подготовленного CAPTCHA-изображения.
- Поддерживает использование различных кодировок в системе распознавания.
Думаю, общий смысл понятен, поэтому предлагаю посмотреть, как это выглядит. Универсальность утилиты не могла не привести к усложнению ее интерфейса, поэтому окно программы может ввести в небольшой ступор. Так что, перед тем как переходить непосредственно к распознаванию капч, предлагаю разобраться с ее интерфейсом и заложенным функционалом.
текста из капчи
About
Мы не могли не сказать хотя бы пары слов об авторе замечательной утилиты TesserCap. Его зовут Гурсев Сингх Калра. Он работает главным консультантом в подразделении профессиональных услуг Foundstone, которое входит в состав компании McAfee. Гурсев выступал на таких конференциях, как ToorCon, NullCon и ClubHack. Является автором инструментов TesserCap и SSLSmart. Помимо этого, разработал несколько инструментов для внутренних нужд компании. Любимые языки программирования — Ruby, Ruby on Rails и C#. Подразделение профессиональных услуг Foundstone®, в котором он трудится, предлагает организациям экспертные услуги и обучение, обеспечивает постоянную и действенную защиту их активов от самых серьезных угроз. Команда подразделения профессиональных услуг состоит из признанных экспертов в области безопасности и разработчиков, имеющих богатый опыт сотрудничества с международными корпорациями и государственными
Интерфейс. Вкладка Main
После запуска программы перед нами предстает окно с тремя вкладками: Main, Options, Image Preprocessing. Основная вкладка содержит элементы управления, которые используются для запуска и остановки теста CAPTCHA-изображения, формирования статистики теста (сколько отгадано, а сколько нет), навигации и выбора изображения для предварительной обработки. В поле для ввода URL-адреса (элемент управления № 1) должен быть указан точный URL-адрес, который веб-приложение использует для извлечения капч. URL-адрес можно получить следующим образом: кликнуть в правой части CAPTCHA-изображения, скопировать или просмотреть код страницы и извлечь URL-адрес из атрибута src тега изображения
Интерфейс. Вкладка Options
Вкладка опций содержит различные элементы управления для конфигурирования TesserCap. Здесь можно выбрать OCR-систему, задать параметры веб-прокси, включить переадресацию и предварительную обработку изображений, добавить пользовательские HTTP-заголовки, а также указать диапазон символов для системы распознавания: цифры, буквы в нижнем регистре, буквы в верхнем регистре, специальные символы.
Теперь о каждой опции поподробней. Прежде всего, можно выбрать OCR-систему. По умолчанию доступна только одна — Tesseract-ORC, так что заморачиваться с выбором тут не придется. Еще одна очень интересная возможность программы — выбор диапазона символов. Возьмем, например, капчу с xakep.ru — видно, что она не содержит ни одной буквы, а состоит только из цифр. Так зачем нам лишние символы, которые только увеличат вероятность некорректного распознавания? Конечно, они нам ни к чему, поэтому при тестировании капчи xakep.ru лучше указать, что она содержит одни цифры: Numerics. Но что если выбрать Upper Case? Сможет ли программа распознать капчу, состоящую из заглавных букв любого языка? Нет, не сможет. Программа берет список символов, используемых для распознавания, из конфигурационных файлов, находящихся в \Program Files\Foundstone Free Tools\TesserCap 1.0\tessdata\configs. Поясню на примере: если мы выбрали опции Numerics и Lower Case, то программа обратится к файлу lowernumeric, начинающемуся с параметра tessedit
Теперь немного о том, для чего нужно поле Http Request Headers. Например, на некоторых веб-сайтах нужно залогиниться, для того чтобы увидеть капчу. Чтобы TesserCap смогла получить доступ к капче, программе необходимо передать в запросе HTTP такие заголовки, как Accept, Cookie и Referrer и т. д. Используя веб-прокси (Fiddler, Burp, Charles, WebScarab, Paros и т. д.), можно перехватить посылаемые заголовки запроса и ввести их в поле ввода Http Request Headers. Еще одна опция, которая наверняка пригодится, — это Follow Redirects. Дело в том, что TesserCap по умолчанию не следует переадресации. Если тестовый URL-адрес должен следовать переадресации для получения изображения, нужно выбрать эту опцию.
Ну и осталась последняя опция, включающая/отключающая механизм предварительной обработки изображений, который мы рассмотрим далее. По умолчанию предварительная обработка изображений отключена. Пользователи сначала настраивают фильтры предварительной обработки изображений согласно тестируемым CAPTCHA-изображениям и затем активируют этот модуль. Все CAPTCHA-изображения, загружаемые после включения опции Enable Image Preprocessing, проходят предварительную обработку и уже затем передаются в OCR-систему Tesseract для извлечения текста.
Интерфейс. Вкладка Image Preprocessing
Ну вот мы и добрались до самой интересной вкладки. Именно тут настраиваются фильтры для удаления с капч различных шумов и размытий, которые стараются максимально усложнить задачу системе распознавания. Процесс настройки универсального фильтра предельно прост и состоит из девяти этапов. На каждом этапе предварительной обработки изображения его изменения отображаются. Кроме того, на странице имеется компонент проверки, который позволяет оценить правильность распознавания капчи при наложенном фильтре. Рассмотрим подробно каждый этап.
Этап 1. Инверсия цвета
На данном этапе инвертируются цвета пикселей для CAPTCHA-изображений. Код, представленный ниже, демонстрирует, как это происходит:
for(each pixel in CAPTCHA)
{
if (invertRed is true)
new red = 255 – current red
if (invertBlue is true)
new blue = 255 – current blue
if (invertGreen is true)
new green = 255 – current green
}
Инверсия одного или нескольких цветов часто открывает новые возможности для проверки тестируемого CAPTCHA-изображения.
Этап 2. Изменение цвета
На данном шаге можно изменить цветовые компоненты для всех пикселей изображения. Каждое числовое поле может содержать 257 (от 1 до 255) возможных значений. Для RGB-компонентов каждого пикселя в зависимости от значения в поле выполняются следующие действия:
- Если значение равно -1, соответствующий цветовой компонент не меняется.
- Если значение не равно -1, все найденные компоненты указанного цвета (красный, зеленый или синий) меняются в соответствии с введенным в поля значением. Значение 0 удаляет компонент, значение 255 устанавливает его максимальную интенсивность и т. д.
Этап 3. Градация серого (Шкала яркости)
На третьем этапе все изображения конвертируются в изображения в градациях серого. Это единственный обязательный этап преобразования изображений, который нельзя пропустить. В зависимости от выбранной кнопки выполняется одно из следующих действий, связанных с цветовой составляющей каждого пикселя:
- Average -> (Red + Green + Blue)/3.
- Human -> (0.21 * Red + 0.71 * Green + 0.07 * Blue).
- Average of minimum and maximum color components -> (Minimum (Red + Green + Blue) + Maximum (Red + Green + Blue))/2.
- Minimum -> Minimum (Red + Green + Blue).
- Maximum -> Maximum (Red + Green + Blue).
В зависимости от интенсивности и распределения цветовой составляющей CAPTCHA любой из этих фильтров может улучшить извлекаемое изображение для дальнейшей обработки.
Изменение помех при изменении различных диапазонов цветового значения пикселей в сторону белого или черногоЭтап 4. Сглаживание и резкость
Чтобы усложнить извлечение текста из CAPTCHA-изображений, в них добавляют шум в форме однопиксельных или многопиксельных точек, посторонних линий и пространственных искажений. При сглаживании изображения возрастает случайный шум, для устранения которого потом используются фильтры Bucket или Cutoff. В числовом поле Passes следует указать, сколько раз нужно применить соответствующую маску изображения перед переходом на следующий этап. Давай рассмотрим компоненты фильтра для сглаживания и повышения резкости. Доступны два типа масок изображения:
- Фиксированные маски. По умолчанию TesserCap имеет шесть наиболее популярных масок изображения. Эти маски могут сглаживать изображение или повышать резкость (преобразование Лапласа). Изменения отображаются сразу же после выбора маски с помощью соответствующих кнопок.
- Пользовательские маски изображения. Пользователь также может настроить пользовательские маски обработки изображений, вводя значения в числовые поля и нажимая кнопку Save Mask. если сумма коэффициентов в этих окошках меньше нуля, выдается ошибка и маска не применяется. При выборе фиксированной маски кнопку Save Mask использовать не требуется.
Этап 5. Вводим оттенки серого
На этом этапе обработки изображения его пиксели могут быть окрашены в широкий диапазон оттенков серого. Этот фильтр отображает распределение градаций серого в 20 бакетах (bucket)/диапазонах. Процент пикселей, окрашенных в оттенки серого в диапазоне от 0 до 12, указан в бакете (bucket) 0, процент пикселей, окрашенных в оттенки серого в диапазоне от 13 до 25, — в бакете (bucket) 1 и т. д. Пользователь может выбрать одно из следующих действий для каждого диапазона значений, соответствующих оттенкам серого:
- Оставить без изменения (Leave As Is).
- Заменить белым (White).
- Заменить черным (Black).
Благодаря этим опциям можно контролировать различные диапазоны оттенков серого, а также сокращать/удалять шум путем, меняя оттенки серого в сторону белого или черного.
Этап 6. Настройка отсечения (cutoff)
Этот фильтр строит график зависимости значения уровня серого от частоты встречаемости и предлагает выбрать отсечение. Принцип работы отсекающего фильтра показан ниже в псевдокоде:
if (pixel’s grayscale value <= Cutoff)
pixel grayscale value = (0 OR 255) -> в зависимости, от того какая опция выбрана (<= или => : Set Every Pixel with value <=/=> Threshold to 0. Remaining to 255)
График показывает подробное распределение пикселей CAPTCHA по цветам и помогает удалить помехи с помощью отсечения значений уровня серого.
Этап 7: Обтесывание (chopping)
После применения сглаживающего, отсекающего, bucket- и других фильтров CAPTCHA-изображения все еще могут быть зашумлены однопиксельными или многопиксельными точками, посторонними линиями и пространственными искажениями. Принцип работы фильтра обтесывания заключается в следующем: если количество смежных пикселей, окрашенных в данный оттенок серого, меньше величины в числовом поле, фильтр обтесывания присваивает им значение 0 (черный) или 255 (белый) по выбору пользователя. При этом CAPTCHA анализируется как в горизонтальном, так и в вертикальном направлении.
Этап 8: Изменение ширины границы
Как утверждает автор утилиты, в ходе первоначальных исследований и разработки TesserCap он неоднократно отмечал, что, когда CAPTCHA-изображения имеют толстую граничную линию и ее цвет отличается от основного фона CAPTCHA, некоторые системы OCR не могут распознать текст. Данный фильтр предназначен для обработки граничных линий и их изменения. Граничные линии с шириной, которая указана в числовом поле, окрашиваются в черный или белый по выбору пользователя.
Этап 9: Инверсия серого оттенка
Этот фильтр проходит каждый пиксель и заменяет его значение уровня серого новым, как показано ниже в псевдокоде. Инверсия серого проводится для подгонки изображения под цветовые настройки OCR-системы.
for(each pixel in CAPTCHA)
new grayscale value = 255 – current grayscale value
Этап 10: Проверка распознавания капчи
Цель данного этапа — передать предварительно обработанное CAPTCHA-изображение OCR-системе для распознавания. Кнопка Solve берет изображение после фильтра инверсии серого, отправляет в OCR-систему для извлечения текста и отображает возвращенный текст в графическом интерфейсе. Если распознанный текст совпадает с текстом на капче, значит, мы правильно задали фильтр для предварительной обработки. Теперь можно перейти на вкладку опций и включить опцию предварительной обработки (Enable Image Preprocessing) для обработки всех последующих загруженных капч.
Распознаем капчи
Ну что ж, пожалуй, мы рассмотрели все опции этой утилиты, и теперь неплохо было бы протестировать какую-нибудь капчу на прочность. Предлагаю для примера взять капчу xakep.ru.
Результат анализа капчи xakep.ru с предварительнойобработкой изображений. Судя по результатам, фильтр
подобрать не удалось
Итак, запускаем утилиту и идем на сайт журнала. Видим список свежих новостей, заходим в первую попавшуюся и пролистываем до места, где можно оставить свой комментарий. Ага, коммент так просто не добавить (еще бы, а то бы давно уже всё заспамили) — нужно вводить капчу. Ну что ж, проверим, можно ли это автоматизировать. Копируем URL картинки и вставляем его в адресную строку TesserCap. Указываем, что нужно загрузить 12 капч, и нажимаем Start. Программа послушно загрузила 12 картинок и попыталась их распознать. К сожалению, все капчи оказались либо не распознаны, о чем свидетельствует надпись -Failed- под ними, либо распознаны неправильно. В общем, неудивительно, так как посторонние шумы и искажения не были удалены. Этим мы сейчас и займемся. Жмем правой кнопкой мыши на одну из 12 загруженных картинок и отправляем ее в систему предварительной обработки (Send To Image Preprocessor). Внимательно рассмотрев все 12 капч, видим, что они содержат только цифры, поэтому идем на вкладку опций и указываем, что распознавать нужно только цифры (Character Set = Numerics). Теперь можно переходить на вкладку Image Preprocessing для настройки фильтров. Сразу скажу, что поигравшись с первыми тремя фильтрами («Инверсия цвета», «Изменение цвета», «Градация серого») я не увидел никакого положительного эффекта, поэтому оставил там всё по дефолту. Я выбрал маску Smooth Mask 2 и установил количество проходов равным одному. Фильтр Grayscale buckets я пропустил и перешел сразу к настройке отсечения. Выбрал значение 154 и указал, что те пиксели, которых меньше, нужно установить в 0, а те, которых больше, в 255. Чтобы избавиться от оставшихся точек, включил chopping и изменил ширину границы до 10. Последний фильтр включать не было смысла, поэтому я сразу нажал на Solve.
На капче у меня было число 714945, но программа распознала его как 711435. Это, как видишь, совершенно неверно. В конечном итоге, как я ни бился, нормально распознать капчу у меня так и не получилось. Пришлось экспериментировать с pastebin.com, которые без проблем удалось распознать. Но если ты окажешься усидчивее и терпеливее и сумеешь получить корректное распознавание капч с xakep.ru, то сразу заходи на вкладку опций и включай предварительную обработку изображений (Enable Image Preprocessing). Затем переходи на Main и, кликнув на Start, загружай свежую порцию капч, которые теперь будут предварительно обрабатываться твоим фильтром. После того, как программа отработает, отметь корректно/некорректно распознанные капчи (кнопки Mark as Correct/Mark as InCorrect). С этого момента можно посматривать сводную статистику по распознаванию с помощью Show Statistics. В общем-то, это своеобразный отчет о защищенности той или иной CAPTCHA. Если стоит вопрос о выборе того или другого решения, то с помощью TesserCap вполне можно провести свое собственное тестирование.
Результат проверки CAPTCHA на популярных сайтах
Веб-сайт и доля распознанных капч:
- Wikipedia > 20–30 %
- Ebay > 20–30 %
- reddit.com > 20–30 %
- CNBC > 50 %
- foodnetwork.com > 80–90 %
- dailymail.co.uk > 30 %
- megaupload.com > 80 %
- pastebin.com > 70–80 %
- cavenue.com > 80 %
Заключение
CAPTCHA-изображения являются одним из самых эффективных механизмов по защите веб-приложений от автоматизированного заполнения форм. Однако слабые капчи смогут защитить от случайных роботов и не устоят перед целенаправленными попытками их решить. Как и криптографические алгоритмы, CAPTCHA-изображения, тщательно протестированные и обеспечивающие высокий уровень безопасности, являются самым лучшим способом защиты. На основе статистики, которую привел автор программы, я выбрал для своих проектов reCaptcha и буду рекомендовать ее всем своим друзьям — она оказалось самой стойкой из протестированных. В любом случае не стоит забывать, что в Сети есть немало сервисов, которые предлагают полуавтоматизированное решение CAPTCHA. Через специальный API ты передаешь сервису изображение, а тот через непродолжительное время возвращает решение. Решает капчу реальный человек (например, из Китая), получая за это свою копеечку. Тут уже никакой защиты нет. 🙂
Автоматический ввод капчи – теория и практика покорения Интернет / Habr
В 2011 году 75-летний юбилей термина «спам» знаменовался вводом капчи 200 миллионов раз ЕЖЕДНЕВНО!Все эти вводы — следствие борьбы администраторов сайтов со спам-ботами.
Автоматизация процесса распознавания капчи для множества людей, активно ведущих бизнес в Интернете, является насущной проблемой. Можно относиться к таким бизнесменам и специалистам как к «нехорошим и надоедливым спамерам». Однако остановить процесс спам-постинга, по крайней мере, в обозримом будущем возможным не представляется.
Ссылочный маркетинг здесь полноценно и уникально сочетает в себе решение задач продвижения, повышения репутации продвигаемого сайта в глазах поисковых систем. Происходит это по той простой причине, что каждая ссылка на сайт (в т.ч. и из спам-поста) повышает его позиции в выдачах Google, Яндекса и т.д. Следовательно, такой способ «убийства двух зайцев одним выстрелом» выгоден изначально. И значительная часть Интернет-бизнесменов должны не бороться со спам-постингом, а пытаться использовать его в своих целях.
Итак, актуальность решения задачи «обход капчи» сомнений не вызывает.
Задача автоматически решается при проведении компаний в ручном режиме, при помощи найма сотен постеров. Но говорить об эффективности такого метода, если не сегодня, то уже завтра не придётся. Да, проблема ввода капчи для заказчика здесь действительно является не актуальной. Но организационные, временные и финансовые затраты при таком способе действий серьёзной критики не выдерживают.
Поэтому уже не первый год активно развиваются специализированные программные продукты — автоматические постеры. Часть из них достаточно известна на рынке (тот же XRumer), часть – разработана и используется только внутри некоторых фирм. В случае применения автоматического постера решение задачи «как обойти капчу» возможно двумя способами:
- её ручным вводом или использованием сервисов, где распознавание производится людьми-операторами;
- дополнением софта постера модулями автоматического распознавания капчи.
Ручной ввод
Отметим сразу, что ручной ввод неприемлем при серьёзных объёмах постинга.
Распознавание капчи сегодня можно поручить специальным сервисам (например, antigate). Цена вопроса – $1-2.5 за тысячу распознаваний. К недостаткам этого метода относятся:
- постоянные финансовые затраты при каждой компании постинга;
- большие временные задержки при распознавании. В среднем капча-сервисы обещают проводить распознавание за
5-20 секунд. Хотя это уже и немало, но фактически это время может оказываться и значительно больше.
Положительной чертой для такого рода сервисов является независимость от типа капчи, поскольку распознавание проводит реальный человек-оператор.
Программное распознавание
На сегодняшний день сложной теоретической и практической проблемой является разработка искусственных систем распознавания графических образов. Оптическое распознавание символов, в применении к капчам – не настолько простая задача, как распознавание отсканированного или рукописного текста, потому что разработчики капч накладывают на символы такие эффекты, чтобы программное распознавание стало невозможным.
Однако, несмотря на это, создание программ распознавания капч – наша специализация. Конечно, к данной деятельности можно относиться по-разному, в том числе, и негативно, однако мы понимаем, что благодаря нашим программам автоматически постятся комментарии в блоги, рассылаются смс рекламного характера, регистрируются почтовые аккаунты для последующего спама. Но то, что мы делаем, можно сравнить с продажей ножей – ножом можно нарезать хлеб, а можно и убить кого-то… Виноват ли в данном случае изготовитель или продавец ножа?.. У каждого – свое мнение…
Универсального программного продукта для распознавания любых типов капчи не существует. Поэтому софт автоматических постеров последовательно дополняется модулями распознавания необходимых её разновидностей. Разработкой такого программного обеспечения занимаются отдельные коллективы, например — мы www.captcha-lab.org. В нашем портфолио демонстрационная программа для ввода капчи представлена не для одного типа. Особый интерес вызывают разработки команды для капчи CMS Bitrix (официально — 1С-Битрикс). Эта CMS не просто популярна в России, а занимает первое место среди платных тиражных «движков». Естественно, что «взлом» капчи Битрикс
интересовал и интересует многих специалистов. В 2006 году даже имела место удачная попытка проделать такую «операцию». Однако затем разработчики CMS Bitrix поменяли тип капчи, и до сих пор она оставалась неуязвимой. Как наглядно демонстрируют демо-программы от www.captcha-lab.org, теперь эта проблема решена с достаточно высокими показателями – 64% и 60% для разных версий Битрикс. Не считаете эти показатели достаточно высокими? Действительно, другие типы капчи софтом выпущенных нашей командой программистов распознаются с вероятностью до 90%. Предела совершенству, действительно, нет. Но и эти показатели являются высокими, достаточными для работы. Отметим, что использование капча-сервиса также обеспечивает правильное распознавание только в 80-95% случаев.
Рис. 1 — Распознавание старой версии капчи CMS Битрикс
Рис. 2 — Распознавание новой версии капчи CMS Битрикс
Во что обойдётся разработка программы для распознавания капчи? $100-500, в зависимости от её типа, сложности. Отметим, что это разовая трата. Таким образом, в отличие от капча-сервисов, автоматическое распознавание позволяет серьёзно выигрывать в цене вопроса. Кроме того, обеспечивается также и существенный выигрыш во времени: распознавание софтом редко занимает более секунды.
Напоминаем, что посмотреть все «сделанные» нами капчи можно на нашем сайте в разделе портфолио.
Скрипт для автоматического ввода капчи – Лайфхакер
Когда на сайте перед вами возникает капча, большинству людей хочется обойтись без ввода символов. Универсальные боты часто не справляются с задачей ввода капчи на конкретном сайте, поэтому сегодня разрабатываются так называемые скрипты, которые позволяют сделать ввод капчи на определенном ресурсе автоматическим.
Когда требуется автоматический ввод капчи
Чаще всего автоматический ввод необходим при выполнении множественных задач на сайте. Например, существуют ресурсы, которые позволяют каждый час получать вознаграждение за активность пользователя. Это сайты по обмену валют, выводу денег, совершению финансовых операции. Пользователям предлагается бонус за выполнение определенных задач, однако проходить вручную проверки постоянно окажется утомительной задачей, именно поэтому созданы специальные скрипты.
текстовые капчи, графические капчи: ReCaptcha V2, KeyCaptcha, FunCaptcha и др.
Зарегистрироваться>>>
Также скрипты помогают при множественной регистрации на сайтах. Так, если вы хотите создать в бизнес-целях десятки и сотни аккаунтов на определенном сайте, то выполнение этой задачи вручную займет несколько дней, тогда как бот способен за час создать сотни аккаунтов, используя автоматический ввод скрипта.
Что такое скрипт для капчи
Скрипт представляет собой запрограммированную задачу, которая выполняется на сайте автоматически.
Например, программист написал скрипт (небольшую программу), который способен самостоятельно проходить регистрацию на ресурсе и создавать учетную запись, или скрипт может получать за вас бонусы за посещение сайта, рассылать рекламу на форуме и выполнять более сложные задачи.
Как правило, для конкретного ресурса требуется отдельный скрипт, так как у каждого сайта своя схема работы: сделать универсальный скрипт оказывается слишком сложно. Скрипт может быть как автоматическим, так и полуавтоматическим, требующий сопровождение со стороны пользователя.
Существуют специальные скрипты, которые способны проходить тест-капчу: обычно они используют информацию из базы данных и подбирают правильный ответ на капчу, а бывает, что скрипт пользуется некоторыми уязвимостями сайта и обходит ввод капчи.
Как работает скрипт для ввода капчи
Чаще всего скрипт представляет собой не отдельную программу, а код для уже существующих программ для работы со скриптами. Одна из самых популярных в мире программ для использования пользовательских скриптов называется Tampermonkey. Это зарубежное программное обеспечение, которое распространяется бесплатно и позволяет использовать на одном сайте множество скриптов одновременно.
Смотрите видео — Установка скрипта с помощью Tampermonkey:
По сути, скрипт не работает сам по себе, а является лишь специальным кодом-командой, по которому внешнее программное обеспечение выполняет заданные задачи. Разработка скрипта является сложной задачей и требует переработку кода конкретного сайта. В код вносятся определенные коррективы, и благодаря этому становится возможным выполнение особых задач.
Где получить скрипт для ввода капчи и как им воспользоваться
Прежде всего, для того чтобы воспользоваться скриптом, необходимо установить программу для работы со скриптами. Если в вашем случае подходит Tampermonkey, то это расширение для браузера можно бесплатно установить для Chrome и Opera. Все что требуется для работы скрипта – добавить его код в Tampermonkey и включить.
Если говорить про крупнейшие сайты, предлагающие скрипты для ввода капчи, то среди них в первую очередь следует выделить antigate.com. На сайте требуется зарегистрироваться, оплатить стоимость скрипта и установить его согласно инструкции. Проблема заключается в том, что многие сайты блокируют использование скриптов, поэтому разработчики вынуждены постоянно обновлять скрипты для обхода защиты, а вам потребуется скачивать новые версии скрипта.
Что же, для обхода или ввода капчи существуют специальные скрипты – они позволяют сделать ввод автоматическим и упростить задачу для пользователя во многих случаях. Все что требуется для работы скрипта – расширение для браузера и уникальный код, который предлагают разработчики скриптов на специализированных сайтах.
Как воспользоваться скриптом для ввода капчи: пример
Вот здесь рассмотрим пример, как установить скрипт с Антигейт, на примере криптовалютного крана.
Антикапча-сервис ручного распознаванияНад распознаванием капчи работают живые люди, поэтому сервису подвластно все, что способен распознать человек:текстовые капчи, графические капчи: ReCaptcha V2, KeyCaptcha, FunCaptcha и др.
Зарегистрироваться>>>
Если вас интересует заработок на вводе капчи или другие способы заработка в Интернете, заходите сюда – 50 способов заработать в Интернете
Андрей Меркулов
Инвестор, учредитель проекта Территория Инвестирования
Владелец ряда активов — доходный дом, доходные квартиры, доходные сайты
Предприниматель, эксперт по трафику, тиражированию бизнеса и бизнес системам
Урок №17. Автоматическое распознавание капчи
В предыдущих видео мы научились создавать сценарий обработки капчи. При этом, капча вводилась вручную. Сейчас мы покажем, как автоматизировать процесс обработки капчи с помощью сервиса Antigate.
Antigate — это сервис для автоматического распознавания капчи. Если мы его подключаем к сценарию, то при нахождении капчи Datacol не будет выдавать ее для ввода пользователю, а отправит в сервис для распознавания. Обычно Antigate обрабатывает изображение от 7 до 15 секунд, после чего возвращает результат обработки.
Не хотите каждый раз вводить капчу вручную? Посмотрев данную видеоинструкцию вы сможете автоматизировать процесс обработки капчи и значительно ускорить скорость парсинга.
Напомним, что в Datacol Вы так-же найдете уже готовые парсера:
Изменим ранее созданный сценарий, чтобы подключить к нему Antigate. Выбираем действие обработки капчи. Устанавливаем Метод распознавания Antigate. Теперь очень важно задать свойства текущей капчи. Благодаря этому процесс автоматического распознавания будет явно быстрее, а главное корректнее. Капча у нас русская. Кроме того, капча чувствительна к регистру символов.
Теперь осталось ввести ключ от API сервиса антигейт. Он задается в параметре сценария antigate_key. Напомним, этот параметр, был автоматически создан при добавлении стандартного блока обработки капчи. Ключ от сервиса можно получить в пользовательской панели сервиса.
Рекомендую увеличить настройку максимальная ставка хотя бы до 10$ за 1000 распознаваний. Подробнее об этой и других настройках сервиса можно почитать в пользовательской панели. Ну и не забудьте пополнить свой баланс.
Осталось протестировать созданный сценарий. Напомню, что для распознавания каптчи сервису потребуется какое то время. Все отработало отлично! Обратите внимание, что в некоторых случаях сервис может некорректно распознать капчу. Однако благодаря условия повторения, которые мы настроили в сценарии, распознавание для каждой страницы может запускаться до 3 раз.
Сохраним сценарий. Запустим кампанию. Видим, что капча была автоматически обработана и мы получили нужные данные. Заметим, что на большинстве сайтов после ввода правильной капчи, она не появляется еще длительное время.
Заработок на капче, распознавание, заработать на антикапче
Captcha
Для капчи важны все знаки препинания и спецзнаки: точка, запятая, дефис (подходит и вместо тире), плюс, кавычки двойные, звездочка, решетка, скобки угловые и круглые, двоеточие, слеш, нижнее подчеркивание, восклицательный и вопросительный знаки, знак доллара и т. п.
Также важен регистр — большие и маленькие буквы нужно соблюдать.
Все пробелы между символами и словами важны.
Вводить нужно все слова через пробел, русские слова — в русской раскладке, английские — в английской.
Отказ от разгадывания по любой причине уменьшает КПД.
Оплачиваются все правильно введенные капчи, начисление вознаграждения — 1 раз в час.
Описание сервиса
Начните зарабатывать на капче, даже если у вас нет опыта – для этой работы вам нужна лишь внимательность и усидчивость. Сервис антикапчи Адвего похож на игру в угадывание, только вы еще получаете за это развлечение настоящие деньги.
Как заработать на капче
Правила очень просты – нажмите «Получить капчу» и введите по буквам все слова, изображенные на картинках, обычно их два, но может быть больше. Также нужно набирать все знаки препинания и символы – проценты, доллары, звездочки и т. п. Все отдельные слова нужно разделять пробелами, в том числе слова из разных картинок.
Каждый час система будет подсчитывать количество правильно разгаданных капч и начислять вознаграждение на счет, откуда заработанное можно будет вывести на кошелек Webmoney, Qiwi или банковскую карту.
Кому подойдет эта работа
Разгадывание капчи станет подходящей работой, если вы ищете работу наборщиком текста – здесь тоже нужно быстро перепечатывать слова без ошибок. Но преимущество заработка на капче в том, что не нужно знать правила грамматики – достаточно печатать буквы и символы так, как их видите.
Сколько можно заработать
Ваш заработок на вводе капчи (антикапче) ограничен лишь временем – в среднем за час начинающий наборщик разгадывает до 300 капч, более опытный – до 500 и больше. За рабочий день можно заработать до 2-3 долларов, а за месяц – до 100 долларов.
Чем больше процент правильных разгадываний – тем выше оплата за 1000 капч, поддерживайте свой КПД выше 90%, чтобы получать максимальный доход.
Рекомендации при распознавании капч:
- соблюдайте регистр букв, если слово написано заглавными буквами, обязательно вводите его именно так.
- английские слова вводите только латиницей, русские – только кириллицей.
- если слово на картинке перевернуто, вводите его правильно, как будто оно не перевернуто; если ввести слово задом наперед, разгадка не будет засчитана.
- если у слова видна только часть буквы, вводите ее полностью, если видно больше половины буквы.
- если на одной картинке видны несколько слов одно над другим, вводите только то, что расположено ближе к середине картинки и не обрезано снизу или сверху.
- старайтесь вводить все спецзнаки – проценты, градусы, доллар, плюс, минус, равно, звездочки и т. п.
Как заработать на разгадывании капчи
Удалённая работа пользуется всё большей популярностью, но многие думают, что для этого нужны какие-то специальные знания и опыт. Конечно, если вы собрались работать онлайн веб-дизайнером и программистом, вам действительно нужно и то, и другое. Однако в сети есть виды заработка, не требующие практически ничего, кроме компьютера и доступа к интернету. Среди них, например, разгадывание капчи.
Пошаговая инструкция по заработку на разгадывании капчи для новичков
Итак, решив получить приятную подработку онлайн и заработать на разгадывании капчи, вам нужно:
- Найти подходящий сервис, предлагающий данный вид получения дохода онлайн. Например, Адвего. Это удачный выбор, ведь биржа обладает безупречной репутацией, существует много лет, пользуется авторитетом. Цена на разгаданные капчи на Адвего будет зависеть от вашего КПД, чтобы получать максимально высокий доход нужно поддерживать его на уровне выше 90%;
- Выбрав сервис, необходимо зарегистрироваться на нём. Предварительно заведите себе электронный кошелёк и банковскую карту. Адвего предлагает выводить полученные деньги на кошельки в Webmoney, Qiwi и карты различных банков;
- На соответствующей странице сервиса нажимаем кнопку «Получить капчу»;
- Вот тут вам потребуются внимательность, усидчивость и умение быстро находить нужную клавишу на клавиатуре! Перед вами будут появляться картинки с различными комбинациями букв, цифр, специальных символов. Причём зачастую в сложно различимом, размытом виде. Вводить все знаки нужно правильно, без ошибок;
- Разгадали, ввели, отправили капчу — получаете следующую. И так, пока глаза не устанут и внимание не притупится;
- Каждый час средства за разгаданные капчи будут поступать на ваш счёт, откуда вы сможете вывести их на свой кошелёк или карту.
Всё просто, согласитесь, что с таким заданием справится даже новичок. Кроме того, заработок на вводе капчи станет отличным тренажёром, повышающим скорость набора текстов. Совсем скоро вы будете машинально выбирать нужные кнопки клавиатуры, быстро набирая комбинации символов. Отличный навык не только для копирайтеров, но и всех, кому приходится набирать тексты в редакторах.
На Адвего подсчитали, сколько можно заработать на капче. 100 ye в месяц. Немного, признаём, но ведь и работа считается одной из самых простых. Для студентов и школьников — неплохой вариант получить карманные деньги. На Адвего, кстати, ввод капчи может приносить бесплатные символы для проверки текстов на уникальность онлайн. Некоторые копирайтеры биржи пользуются такой возможностью.
Текстовые капчи легко распознаются нейронными сетями глубокого обучения / Habr
Нейронные сети глубокого обучения достигли больших успехов в распознавании образов. В тоже время текстовые капчи до сих пор используются в некоторых известных сервисах бесплатной электронной почты. Интересно смогут ли нейронные сети глубоко обучения справится с задачей распознавания текстовой капчи? Если да то как?
Что такое текстовая капча?
Капча (англ. “CAPTCHA”) — это тест на “человечность”. То есть задача, которую легко решает человек, в то время как для машины эта задача должна быть сложной. Зачастую используется текст со слипшимися буквами, пример на картинке ниже, также картинку дополнительно подвергают оптическим искажениям.
Капча, как правило, используется на странице регистрации для защиты от ботов рассылающих спам.
Полносверточная нейронная сеть
Если буквы “слиплись”, то их обычно очень трудно разделить эвристическими алгоритмами. Следовательно, нужно искать каждую букву в каждом месте картинки. С этой задачей справится полносверточная нейронная сеть. Полносверточная сеть — сверточная сеть без полносвязного слоя. На вход такой сети подается изображение, на выходе она выдает тоже изображение или несколько изображений (карты центров).
Количество карт центров равно длине алфавита символов использованных в определенной капче. На картах центров отмечаются центры букв. Масштабное преобразование, которое в сети происходит из-за наличия пуллинг слоев, учитывается. Ниже показан пример карты символа для символа “D”
В данном случае используются сверточные слои с паддингом так, чтобы размер изображений на выходе сверточного слоя равнялся размеру изображений на входном слое. Профиль пятна на карте символа задается двумерной гауссовой функцией с ширинами 1.3 и 2.6 пикселей.
Первоначально полносверточная сеть была проверена на символе “R”:
Для проверки применялась небольшая сеть с 2мя пуллингами, натреннированная на CPU. Убедившись, что идея хоть как то работает, я приобрел б/у видеокарту Nvidia GTX 760, 2GB. Это дало мне возможность тренировать более крупные сети для всех символов алфавита, а также ускорило обучение (примерно в 10 раз). Для тренировки сети использовалась библиотека Theano, на текущий момент уже не поддерживаемая.
Тренировка на генераторе
Разметить большой датасет вручную казалось делом долгим и трудозатратным, поэтому было решено генерировать капчи специальным скриптом. При этом карты центров генерируются автоматически. Мною был подобран шрифт, используемый в капче для сервиса Hotmail, сгенерированная капча визуально была похожа по стилю на реальные капчи:
Финальная точность тренировки на сгенерированных капчах, как оказалось, в 2 раза ниже, по сравнению с тренировкой на реальных капчах. Вероятно, такие нюансы как степень пересечения символов, масштаб, толщина линий символов, параметры искажения и т. п., важны, и в генераторе эти нюансы воспроизвести не удалось. Сеть тренированная на сгенерированных капчах давала точность на реальных капчах около 10%, точность — какой процент капч распознался правильно. Капча считается распознанной, если все символы в ней распознаны правильно. В любом случае этот эксперимент показал, что метод рабочий, и требуется повысить точность распознавания.
Тренировка на реальном датасете
Для ручной разметки датасета реальных капч был написан скрипт на Matlab с графическим интерфейсом:
Здесь кружочки можно расставлять и двигать мышкой. Кружочком отмечается центр символа. Ручная разметка занимала 5-15 часов, однако есть сервисы, где за не большую плату размечают вручную датасеты. Однако, как оказалось, сервис Amazon Mechanical Turk не работает с российскими заказчиками. Разместил заказ на разметку датасета на известном сайте фриланса. К сожалению, качество разметки было не идеальным, поправлял разметку самостоятельно. Кроме того, поиск исполнителя занимает время (1 неделя) и также это показалось дорого: 30 долларов за 560 размеченных капч. От данного способа отказался, в итоге пришел к использованию сайтов ручного распознавания капч, где самая низкая стоимость 1 доллар за 2000 капч. Но полученный ответ там — это строка. Таким образом, ручной расстановки центров избежать не удалось. Более того, исполнители в таких сервисах допускают ошибки или вовсе действуют недобросовестно, печатая произвольную строку в ответе. В итоге приходилось проверять и исправлять ошибки.
Более глубокая сеть
Очевидно точность распознавания была недостаточна, поэтому возник вопрос подбора архитектуры. Меня интересовал вопрос “видит” ли один пиксель на выходном изображении весь символ на входном изображении:
Таким образом, мы рассматриваем один пиксель на выходном изображении, и есть вопрос: значения каких пикселей на входном изображении влияют на значения этого пикселя? Я рассуждал так: если пиксель видит не весь символ, то используется не вся информация о символе и точность хуже. Для определения размера этой области видимости (будем называть ее так), я провел следующий эксперимент: установил все веса сверточных слоев равным 0.01, а смещения равным 0, на вход сети подается изображение, в котором значения всех пикселей равны 0 кроме центрального. В результате на выходе сети получается пятно:
Форма данного пятна близка к форме гауссовой функции. Форма получившегося пятна вызывает вопрос, почему пятно круглое, тогда как ядра сверток в сверточных слоях квадратные? (В сети использовались ядра сверток 3×3 и 5×5). Мое объяснение такое: это похоже на центральную предельную теорему. В ней, как и здесь, присутствует стремление к гауссовому распределению. Центральная предельная теорема утверждает, что для случайных величин, даже с разными распределениями, распределение их суммы равно свертке распределений. Таким образом, если мы сворачиваем любой сигнал сам с собой много раз, то по центральной предельной теореме результат стремится к гауссовой функции, а ширина гауссовской функции растет как корень из количества сверток (слоев). Если для такой же сети с константными весами посмотреть, где в выходном изображении значения пикселей больше нуля, то получается все таки квадратная область (см. рисунок ниже), размер этой области пропорционален сумме размеров сверток в сверточных слоях сети.
Раньше думал, что из-за ассоциативного свойства свертки две последовательные свертки 3×3 эквивалентны свертке 5×5 и потому, если свернуть 2 ядра 3×3 получится одно ядро 5×5. Однако, потом пришел к выводу, что это не эквивалентно хотя бы потому, что у двух сверток 3×3 9*2=18 параметров, а у одной 5×5 25 параметров, таким образом, у свертки 5×5 больше степеней свободы. В итоге, на выходе сети получается гауссова функция с шириной меньше суммы размеров сверток в слоях. Здесь ответил на вопрос какие пиксели на выходе подвержены влиянию одного пикселя на входе. Хотя изначально вопрос ставился обратный. Но оба вопросы эквивалентны, что можно понять из рисунка:
На рисунке можно представить, что это вид на изображения с боку или, что у нас высота изображений равна 1. Каждый из пикселей A и B имеет свою зону влияния на выходном изображении (обозначены синим цветом): для А это D-C, для B это C-E, на значения пикселя C влияют значения пикселей A и B и значения всех пикселей между A и B. Расстояния равны: AB = DC = CE (с учетом масштабирования: в сети присутствуют пуллинг слои, поэтому входное и выходное изображения имеют разные разрешения). В итоге, получается следующий алгоритм нахождения размера области видимости:
- задаем константные веса в сверточных слоях, весам-смещениям задаем значения 0
- на вход подаем изображения с одним ненулевым пикселем
- получаем размер пятна на выходе
- умножаем этот размер на коэффициент учитывающий разное разрешение входного и выходного слоя (например, если у нас 2 пулинга в сети, то разрешение на выходе в 4 раза меньше, чем на входе, значит этот размер надо умножать на 4).
Чтобы посмотреть какие признаки сеть использует, провел следующий эксперимент: в тренированную сеть подаем изображение капчи, на выходе получаем изображения с отмеченными центрами символов, из них выбираем какой-нибудь задетектированный символ, на изображениях-картах центров оставляем ненулевой только ту карту, которая соответствует рассматриваемому символу. Такой выход сети запоминаем как , затем градиентным спуском минимизируем функцию:
Здесь — входное изображение сети, — выходные изображения сети, — некоторая константа, которая подбирается экспериментально (). При такой минимизации вход и выход сети считаются переменными, а веса сети константами. Начальное значение переменной это изображение капчи, является начальной точкой оптимизации алгоритма градиентного спуска. При такой минимизации мы уменьшаем значения пикселей на входе изображения, при этом сдерживаем значения пикселей на выходном изображении, в результате оптимизации на входном изображении остаются только те пиксели, которые сеть использует в распознавании символа.
Что получилось:
Для символа “2”:
Для символа “5”:
Для символа “L”:
Для символа “u”:
Изображения слева — исходные изображения капч, изображения справа — это оптимизированное изображение . Квадратом на изображениях обозначена область видимости output>0, окружности на рисунке — это линии уровня Гауссовой функции области видимости. Малая окружность — уровень 35% от максимального значения, большая окружность — уровень 3%. Примеры показывают, что сеть видит в пределах своей области видимости. Однако, у символа “u” наблюдается выход за область видимости, возможно это частичное ложное срабатывание на символ “n”.
Было проведено много экспериментов с архитектурой сети, чем более глубокая и широкая сеть, тем более сложные капчи она может распознавать, самой универсальной архитектурой оказалась следующая:
Синим цветом, поверх стрелок, показано количество изображений (feature maps). c- сверточный слой, p — max-pooling слой, зеленым цветом внизу показаны размеры ядер. В сверточных слоях используются ядра 3×3 и 5×5 без strade, пуллинг слой имеет патч 2×2. После каждого сверточного слоя есть ReLU слой (на рисунке не показан). На вход подается одно изображение, на выходе получется 24 (количество символов в алфавите). В сверточных слоях паддинг подобран таким образом, чтобы на выходе слоя размер изображения был таким же как и на входе. Паддинг добавляет нули, однако это никак не влияет на работу сети, потому что значение фонового пикселя капчи — 0, так как всегда берется негативное изображение (белые буквы по черному фону). Паддинг лишь незначительно замедляет работу сети. Так как в сети 2 пуллинг слоя, то разрешение изображения на выходе в 4 раза меньше разрешения изображения на входе, таким образом каждый пуллинг уменьшает разрешение в 2 раза, например, если на входе у нас капча размером 216×96 то на выходе будет 24 изображения размером 54×24.
Улучшения
Переход от решателя SGD к решателю ADAM дал заметное ускорение обучения, и финальное качество стало лучше. Решатель ADAM импортировал из модуля lasagne и использовал внутри theano-кода, параметр learning rate ставил 0.0005, регуляризация L2 была добавлена через градиент. Было замечено, что от тренировки к тренировке результат получается разный. Объясняю это так: алгоритм градиентного спуска застревает в недостаточно оптимальном локальном минимуме. Частично поборол это следующим образом: запускал тренировку несколько раз и выбирал несколько самых лучших результатов, затем продолжал их тренировать еще несколько эпох, после из них выбирал один лучший результат и уже этот единственный лучший результат долго тренировал. Таким образом удалось избежать застревания в недостаточно оптимальных локальных минимумах и финальное значение функции ошибок (loss) получалась достаточно малым. На рисунке показан график — эволюция значения функции ошибок:
По оси x — число эпох, по оси y — значение функции ошибок. Разными цветами показаны разные тренировки. Порядок обучения примерно такой:
1) запускаем 20 тренировок по 10 эпох
2) выбираем 10 лучших результатов (по наименьшему значению loss) и тренируем их еще 100 эпох
3) выбираем один лучший результат и продолжаем тренировать его еще 1500 эпох.
Это занимает около 12 часов. Конечно, для экономии памяти, данные тренировки проводились последовательно, например, в пункте 2) 10 тренировок проводились последовательно одна за другой, для этого провел модификацию решателя ADAM от Lasagne, чтобы иметь возможность сохранять и загружать состояние решателя в переменные.
Разбиение датасета на 3 части позволяло отслеживать переобучение сети:
1 часть: тренировочный датасет — исходный, на котором сеть обучается
2 часть: тестовый датасет, на котором сеть проверяется в процессе тренировки
3 часть: отложенный датасет, на нем проверяется качество обучения после тренировки
Датасеты 2 и 3 небольшие, в моем случае было по 160 капч в каждом, также по датасету 2 определяется оптимальный порог срабатывания, порог который устанавливается на выходное изображение. Если значение пикселя превышает порог, то в данном месте обнаружен соответствующий символ. Обычно оптимальное значение порога срабатывания находится в диапазоне 0.3 — 0.5. Если точность на тестовом датасете значительно ниже, чем точность на тренировочном датасете — это значит что произошло переобучение и тренировочный датасет необходимо увеличить. В случае, если эти точности примерно одинаковы, но не высокие, то архитектуру нейронной сети нужно усложнять, а тренировочный датасет увеличивать. Усложнять архитектуру сети можно двумя путями: увеличивать глубину или увеличивать ширину.
Предварительная обработка изображений также повышала точность распознавания. Пример предобработки:
В данном случае методом наименьших квадратов найдена средняя линия повернутой строки, производится поворот и масштабирование, масштабирование проводится по средней высоте строки. Сервис Hotmail часто делает разнообразные искажения:
Эти искажения необходимо компенсировать.
Неудачные идеи
Всегда интересно почитать про чужие неудачи, опишу их здесь.
Существовала проблема малого датасета: для качественного распознавания требовался большой датасет, который требовалось разметить вручную (1000 капч). Мной предпринимались различные попытки каким-то образом обучить сеть качественно на малом датасете. Делал попытку обучать сеть на результатах распознавания другой сети. при этом выбирал только те капчи и те места изображений, в которых сеть была уверена. Уверенность определял по значению пикселя на выходном изображении. Таким образом можно увеличить датасет. Однако идея не сработала, после нескольких итераций обучения качество распознавания сильно ухудшилось: сеть не распознавала некоторые символы, путала их, то есть ошибки распознавания накапливались.
Другая попытка обучиться на малом датасете — использовать сиамские сети, сиамская сеть на входе требует пару капч, если у нас датасет из N капч, то пар будет N2, получаем гораздо больше обучающих примеров. Cеть преобразует капчу в карту векторов. В качестве метрики сходства векторов выбрал скалярное произведение. Предполагалось что сиамская сеть будет работать следующим образом. Сеть сравнивает часть изображения на капче с некоторым эталонным изображением символа, если сеть видит, что символ тот же с учетом искажения, то считается, что в данном месте качи есть соответствующий символ. Сиамская сеть тренировалась с трудом, часто застревала в неоптимальном локальном минимуме, точность была заметно ниже точности обычной сети. Возможно проблема была в неправильном выборе метрики сходства векторов.
Также была идея использовать автоэнкодер для предварительного обучения нижней части сети (та, что ближе к входу), чтобы ускорить обучение. Автоэнкодер — это сеть, которая обучается выдавать на выходном изображении то же что и подается на вход, при этом в архитектуре автоэнкодера организуют узкий участок. Тренеровка автоэнкодера есть обучение без учителя.
Пример работы автоэкодера:
Первое изображение — входное, второе — выходное.
У обученного автоэнкодера берут нижнюю часть сети, добавляют новых необученных слоев, все это дотренировывают на требуемую задачу. В моем случае применение автоэнкодера никак не ускоряло обучение сети.
Также был пример капчи, которая использовала цвет:
На данной капче описанный метод с полносверточной нейронной сетью не давал результата, он не появился даже после различных предобработок изображения повышающих контрастность. Предполагаю что, полносверточные сети плохо справляются с неконтрастными изображениями. Тем не менее, данную капчу удалось распознать обычной сверточной сетью с полносвязным слоем, получена точность около 50%, определение координат символов осуществлялось специальным эвристическим алгоритмом.
Результат
| Примеры | Точность | Коментарий |
|---|---|---|
| 42 % | Капча Микрософт , jpg |
|
| 61 % | ||
| 63 % | ||
| 93 % | капча mail.ru, 500×200, jpg | |
| 87 % | капча mail.ru, 300×100, jpg | |
| 65 % | Капча Яндекс, русские слова, gif | |
| 70 % | капча Steam, png | |
| 82 % | капча World Of Tanks, цифры, png |
Что еще можно было бы улучшить
Можно было бы сделать автоматическую разметку центров символов. Сервисы ручного распознавания капч выдают лишь распознанные строки, поэтому автоматическая разметка центров помогла бы полностью автоматизировать разметку тренировочного датасета. Идея такова: выбрать только те капчи, в которых каждый символ встречается один раз, на каждый символ натренировать отдельную обычную сверточную сеть, такая сеть будет отвечать лишь на вопрос: есть ли в данной капче символ или нет? Затем посмотреть какие признаки использует сеть, используя метод минимизация значений пикселей входной картинки (описано выше). Полученные признаки позволят локализовать символ, далее тренируем полносверточную сеть на полученных центрах символов.
Выводы
Текстовые капчи распознаются полносверточной нейронной сетью в большинстве случаев. Вероятно, уже настало время отказываться от текстовых капч. Google давно не использует текстовую капчу, вместо текста предлагаются картинки с различными предметами, которые нужно распознать человеку:
Однако и такая задача кажется решаемой для сверточной сети. Можно предположить, что в будущем возникнут центры регистрации людей, например, человека по скайпу интервьюирует живой человек, проверяет сканы паспортов и тому подобное, затем человеку выдается цифровая подпись, с которой он может автоматически регистрироваться на любом сайте.
© Максим Веденев
Автоматическое распознавание капчи в Instagram / Верификация через ReCaptcha … / Общая / SocialKit
Чаще всего Instagram запрашивает верификацию через отправку кода на сопоставленный с аккаунтом номер телефона или E-Mail. Однако, иногда встречаются более сложные и составные запросы на верификацию. Одним из таких запросов является составная верификация, на одном из этапов которой нужно разгадать капчу от Google.
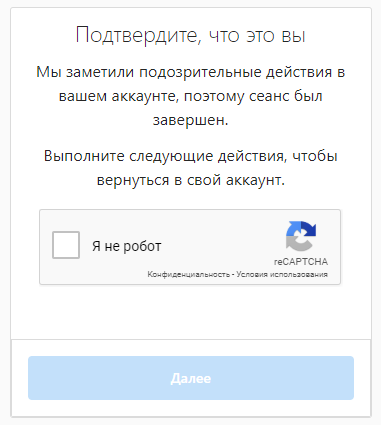
Запрос от Instagram на прохождение Google-капчи.
Выглядит этот запрос на верификацию примерно так, как показано на скриншоте выше. Нередко после установки флага в поле «Я не робот» проверяется человеческий фактор — Google просит что-либо определить на изображениях.
После успешного прохождения Google-капчи Instagram запрашивает новый телефонный номер или E-Mail, а потом дополнительно отправляет код верификации в соответствии с введенным номером или E-Mail’ом.
SocialKit умеет идентифицировать и автоматически проходить такие запросы на верификацию. Для автоматического их прохождения вам потребуется подключить один из поддерживаемых сервисов по распознаванию капчи, а также один из поддерживаемых SMS-сервисов. Все они находятся на подзакладке «Настройки» -> «Сервисы» в главном окне.
Обратите внимание, что после прохождения всех запросов на верификацию Instagram отправляет накопленные данные на свои сервера для более детального анализа. Если это произошло, то работа с аккаунтом на время блокируется.
В таких случаях при работе из официального приложения Instagram на экране отображается следующее:
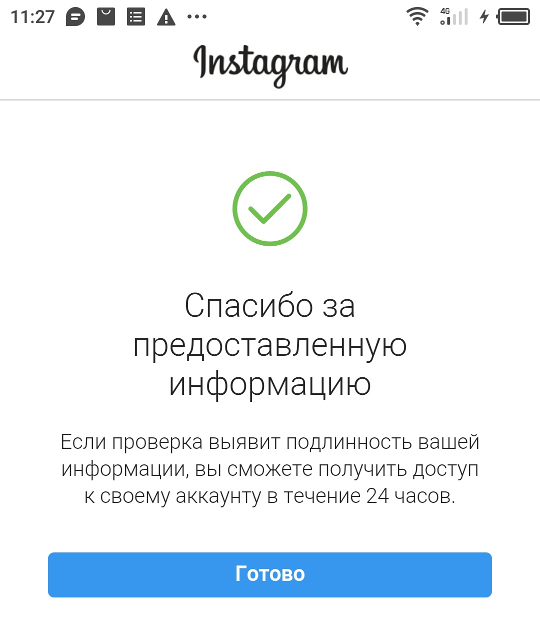
Уведомление о том, что собранные в ходе верификации данные отправлены на сервера Instagram для анализа.
ВАЖНО! Получить доступ к аккаунту до тех пор, пока это не разрешит сделать Instagram невозможно. Соответственно, SocialKit автоматически распознаёт подобные диалоговые формы и выводит в лог соответствующую информацию.

SocialKit распознал информационные диалог о том, что данные отправлены в Instagram для анализа.
Спустя 24 часа можно повторно выполнить полную инициализацию Instagram-аккаунта из SocialKit. Если верить тому, что написано в данном диалоге, то Instagram должен вернуть доступ к аккаунту или окончательно его заблокировать.